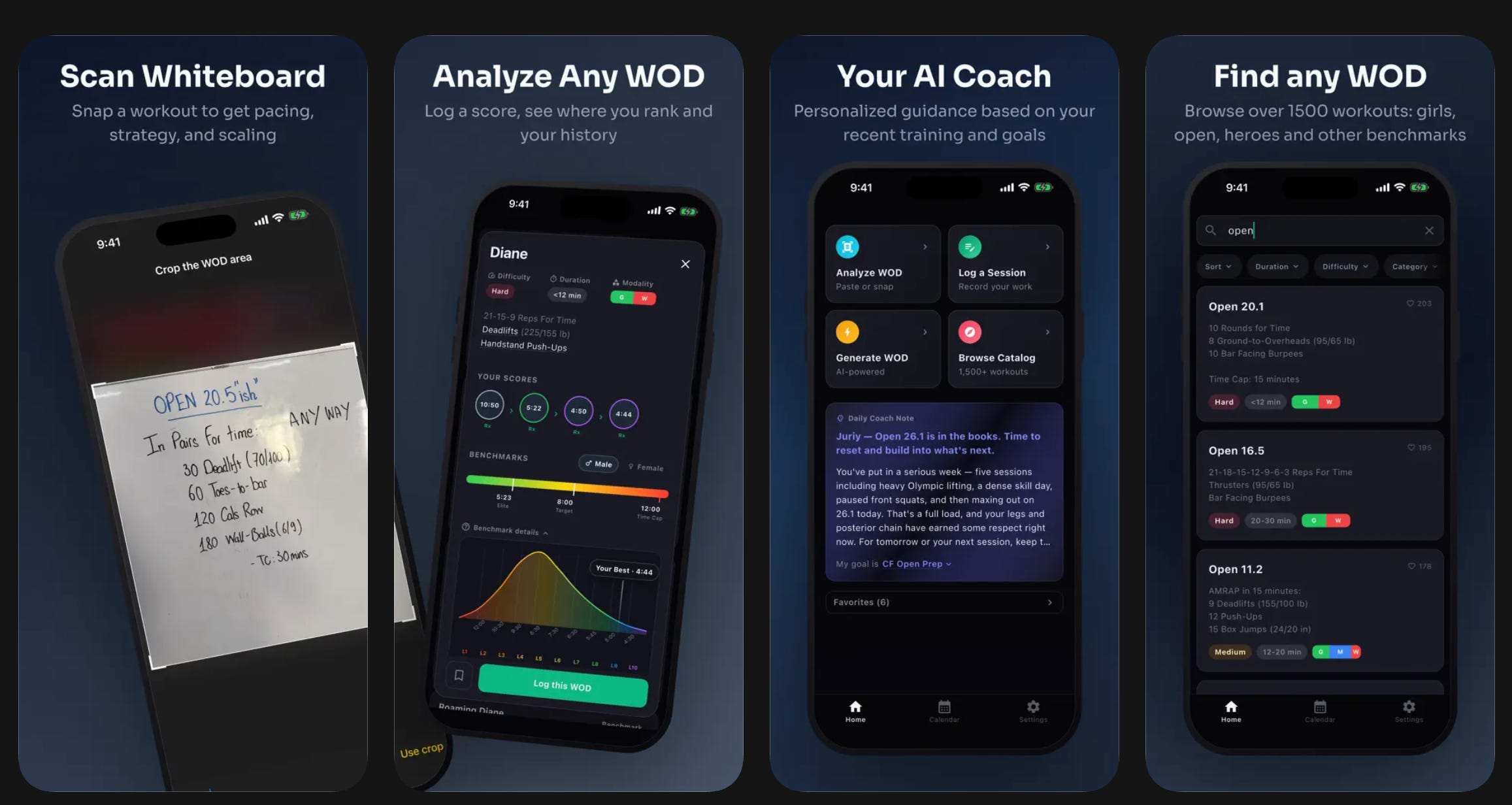
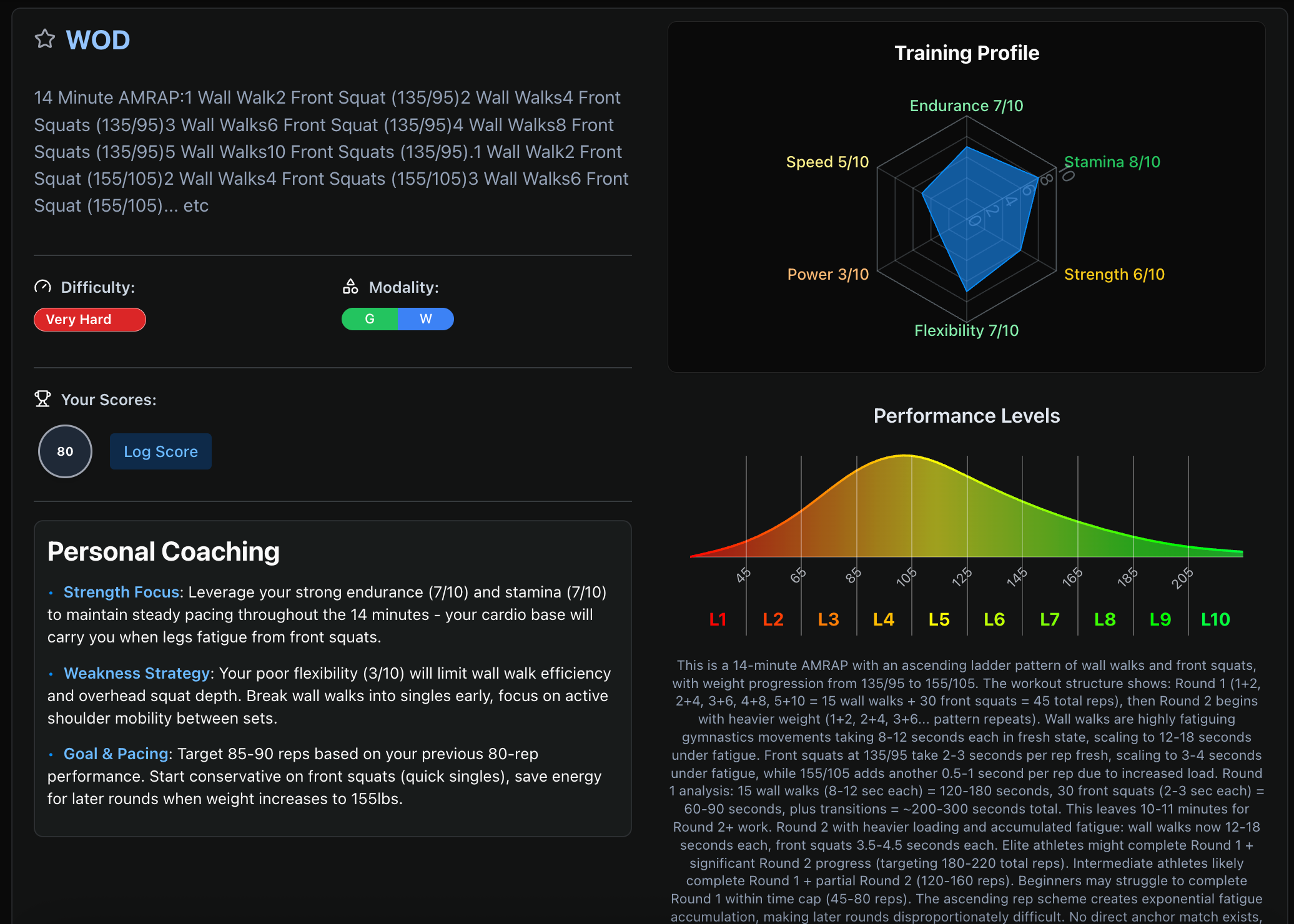
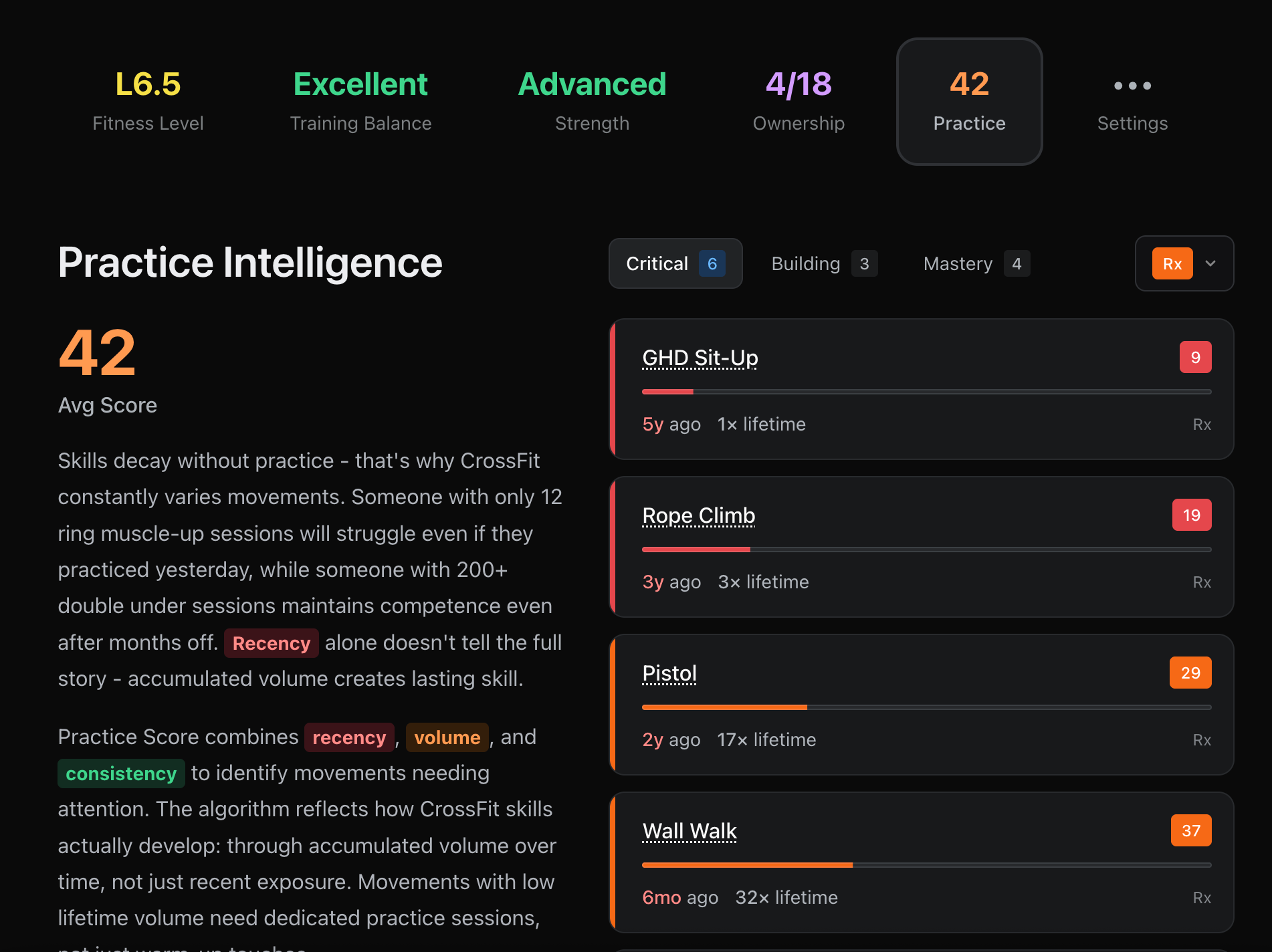
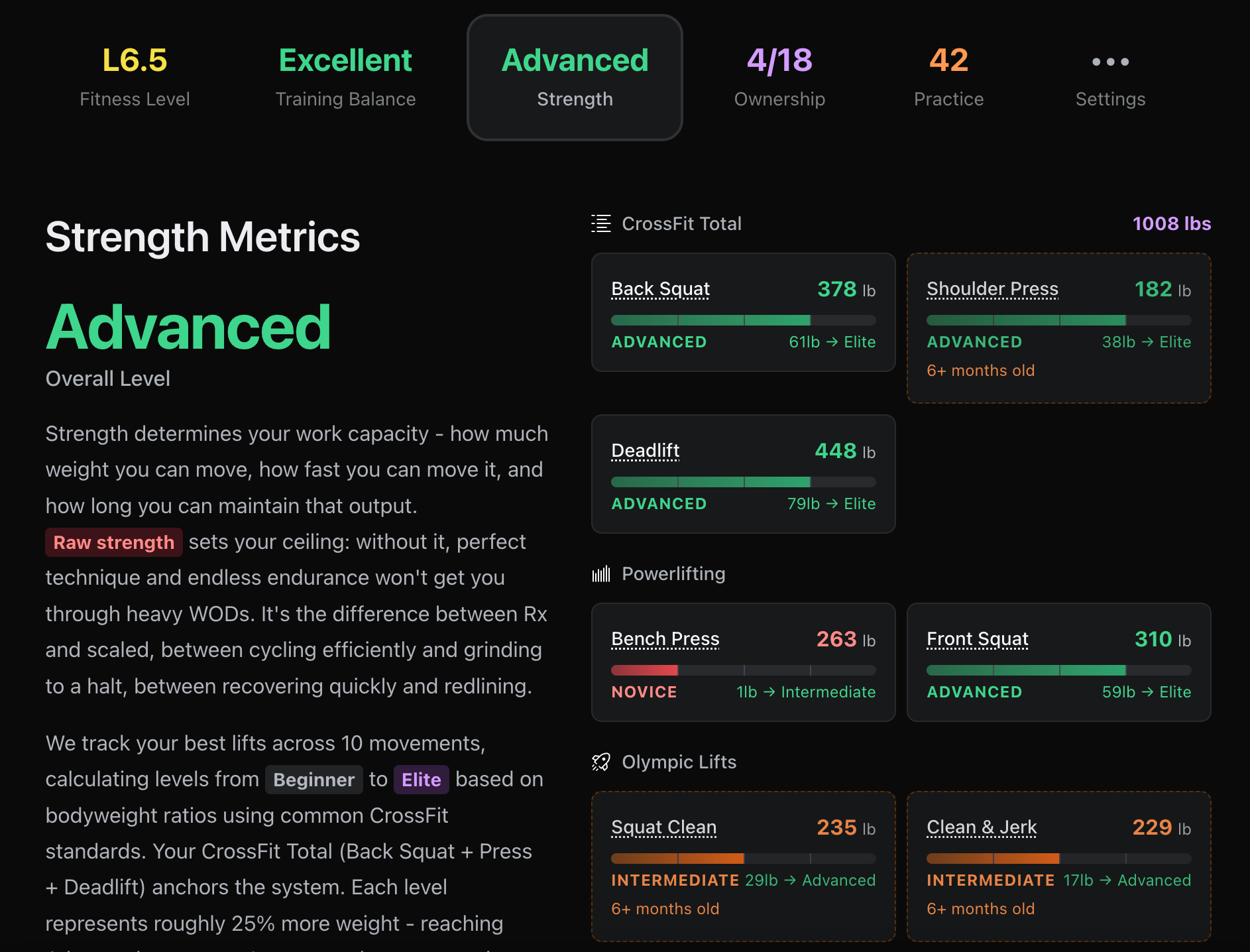
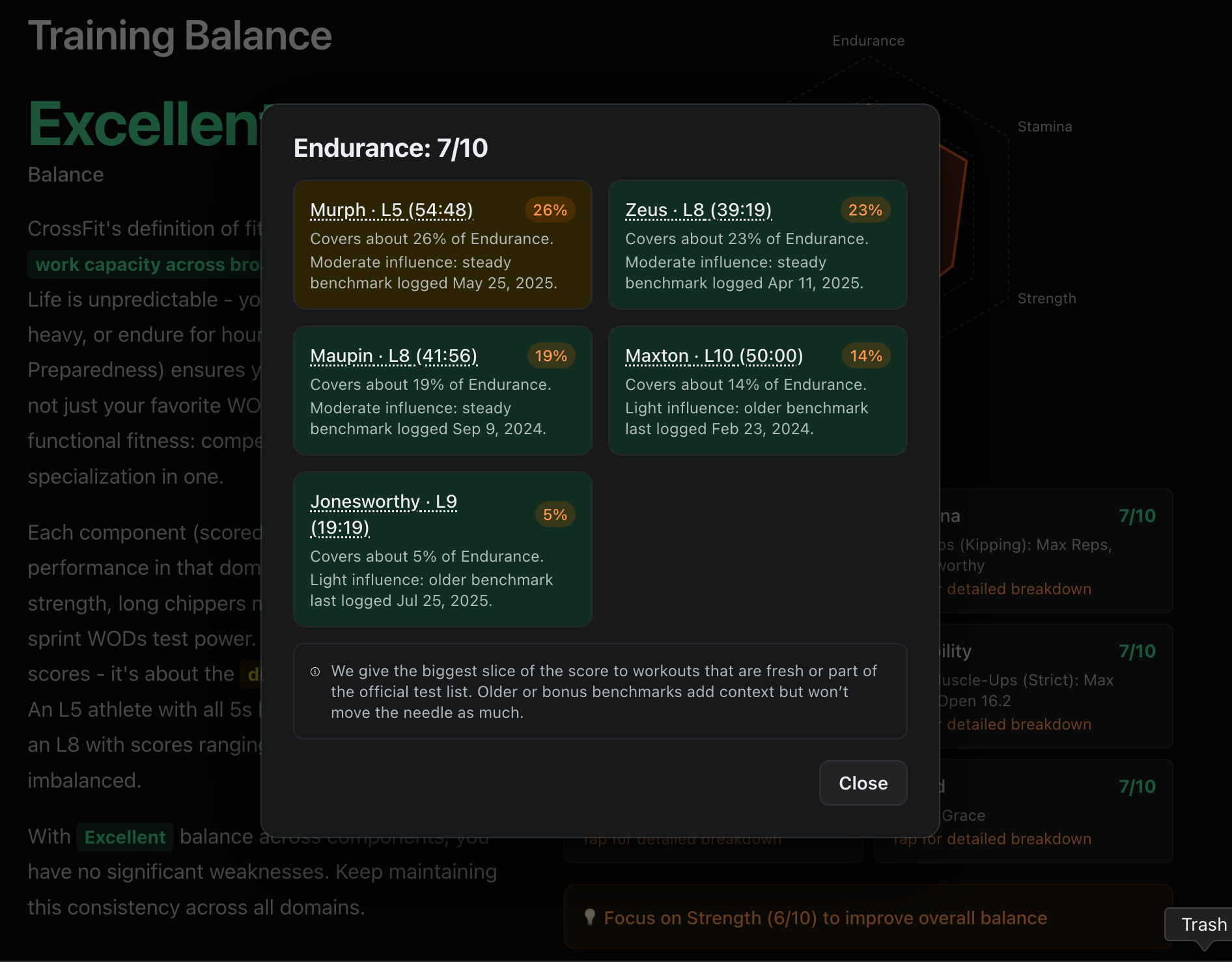
Show full content
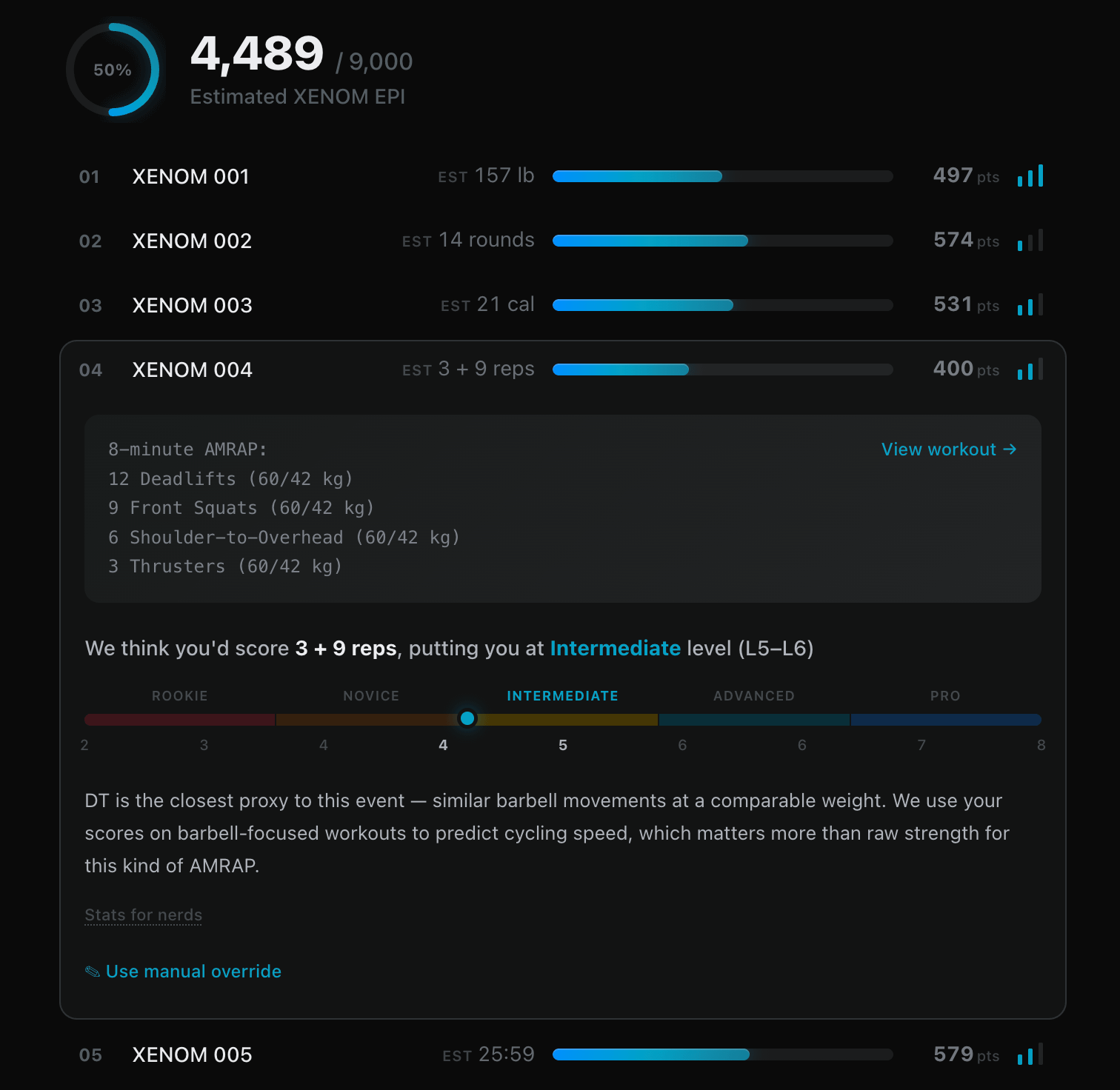
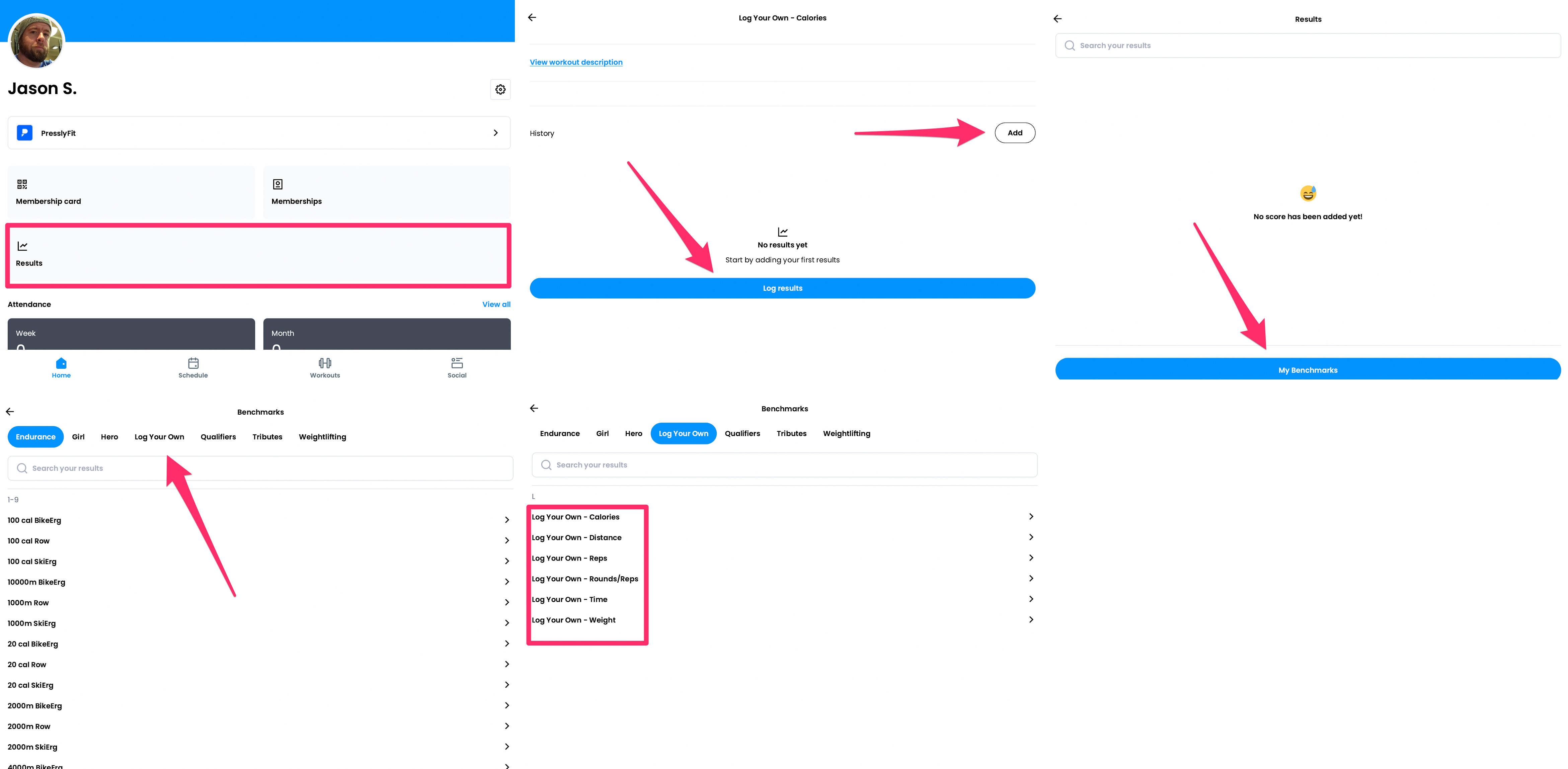
CrossFit apps are good at storing WOD scores, but are terrible at knowing the work you’ve actually done. Here’s a WOD from my box:
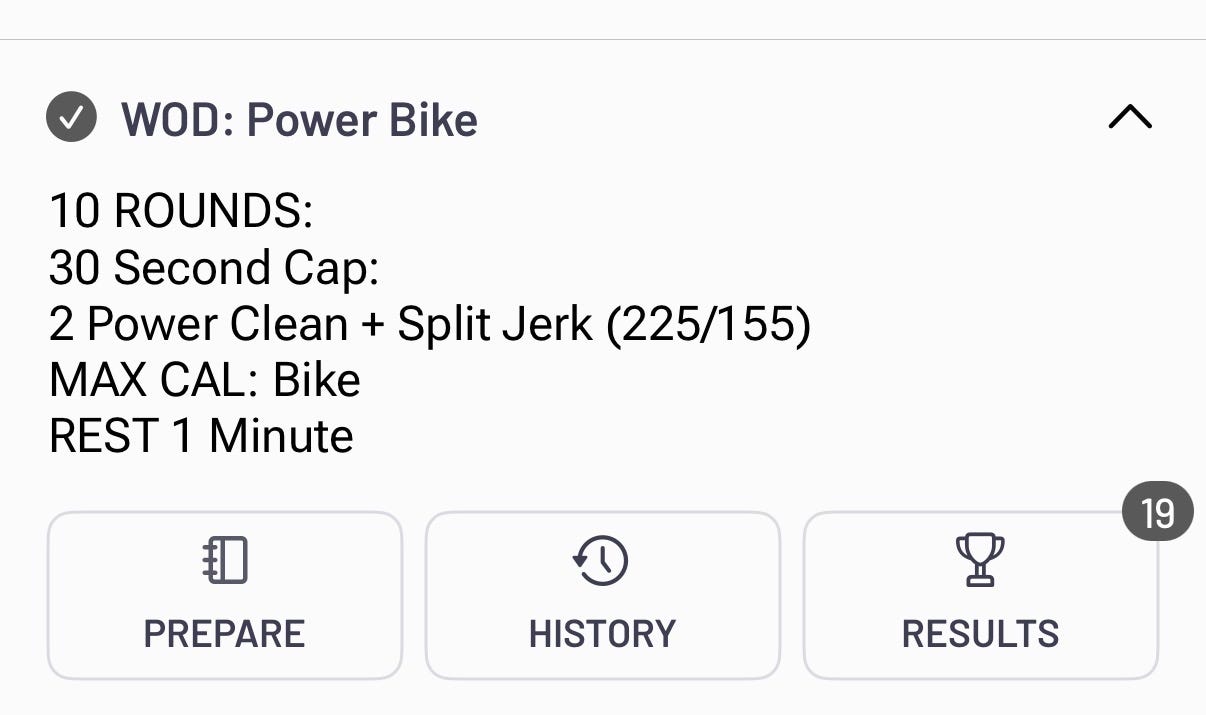
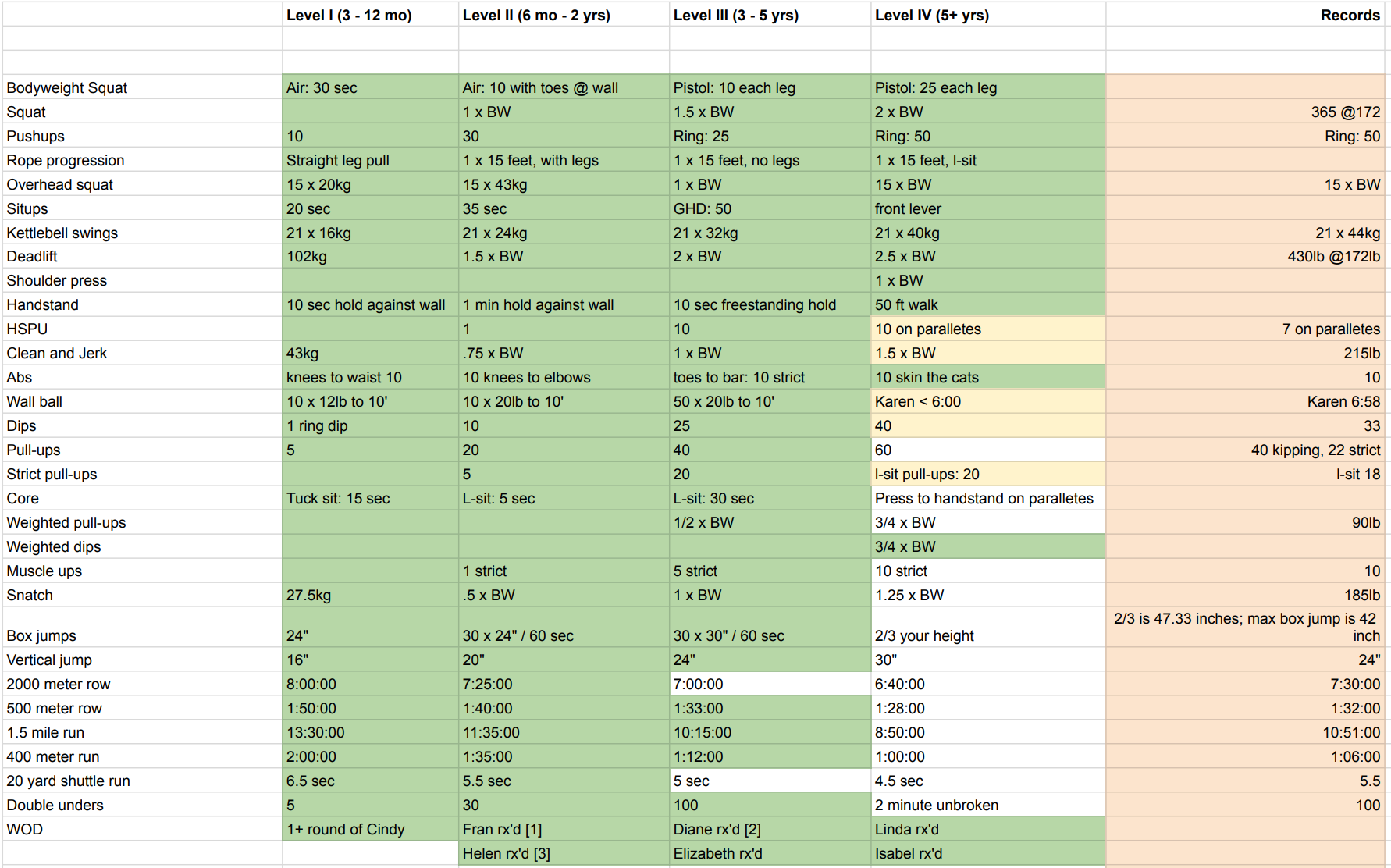
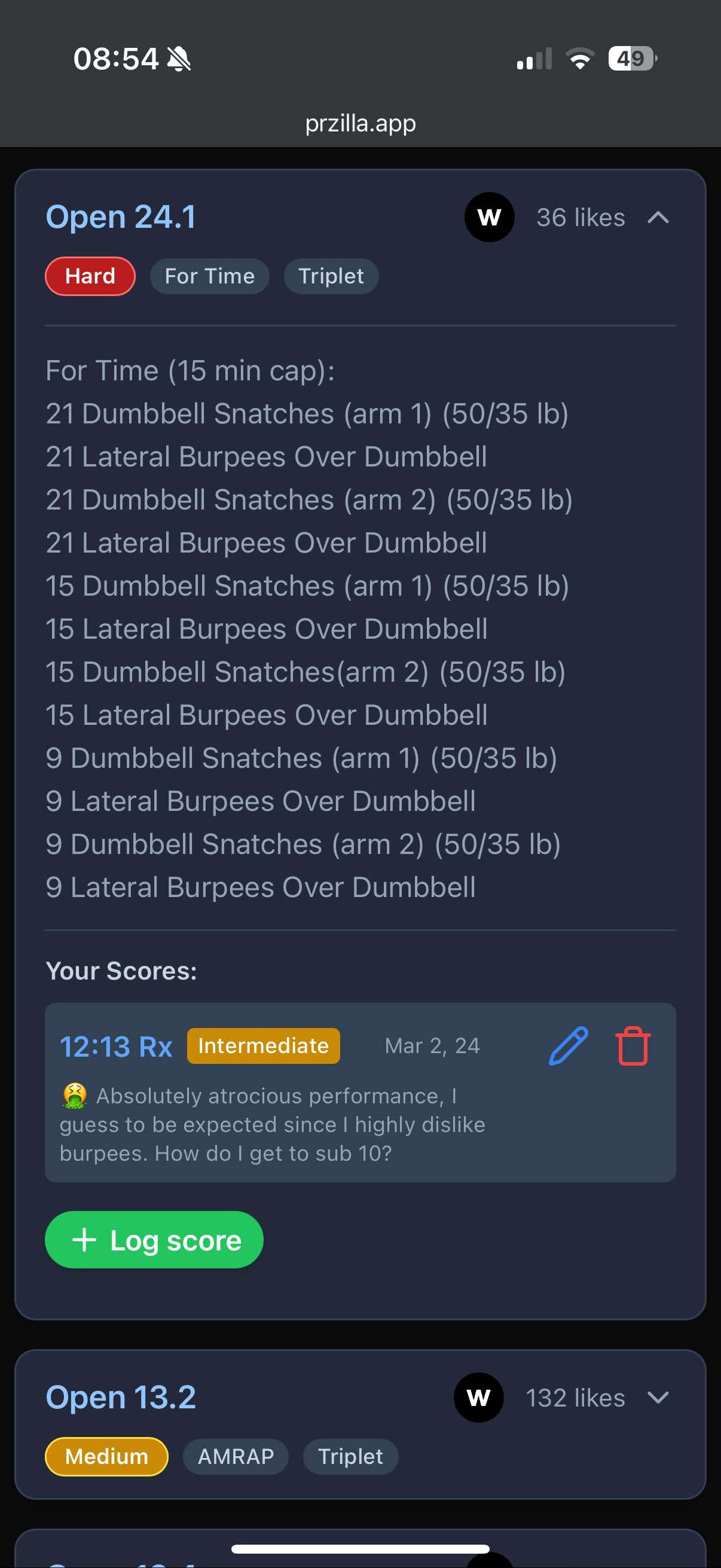
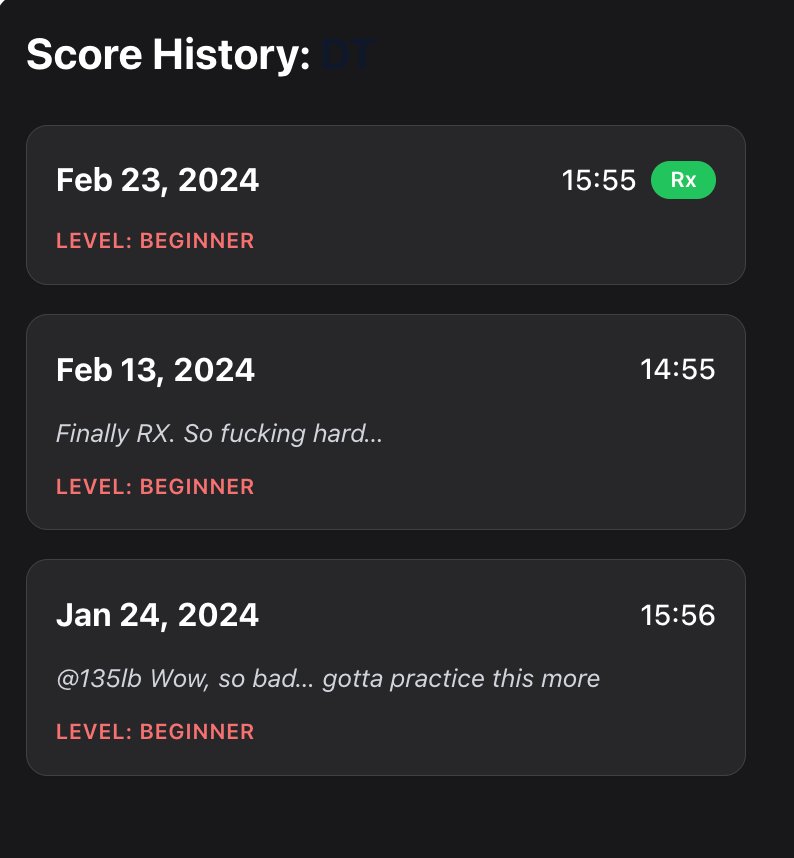
Out of 20 results, only 1 person did it RX:
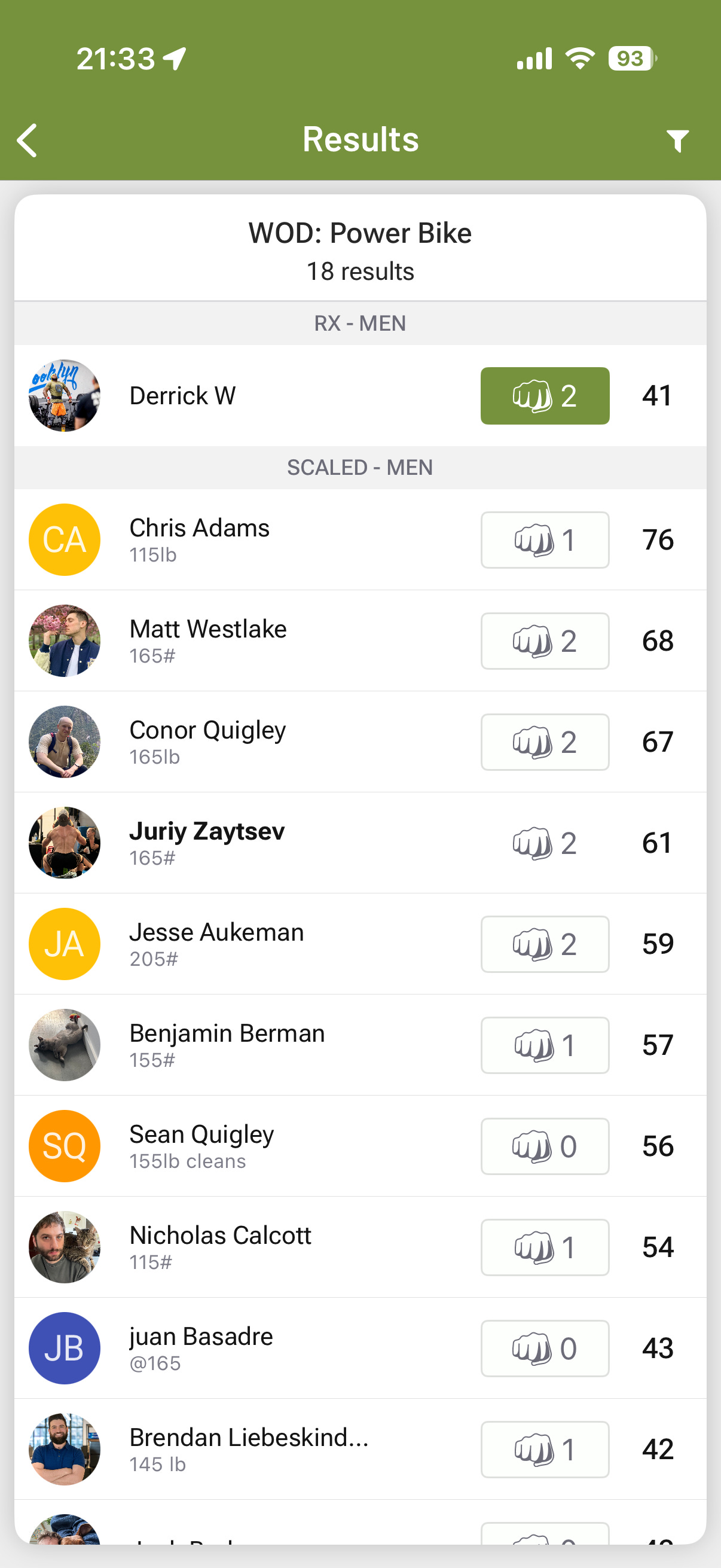
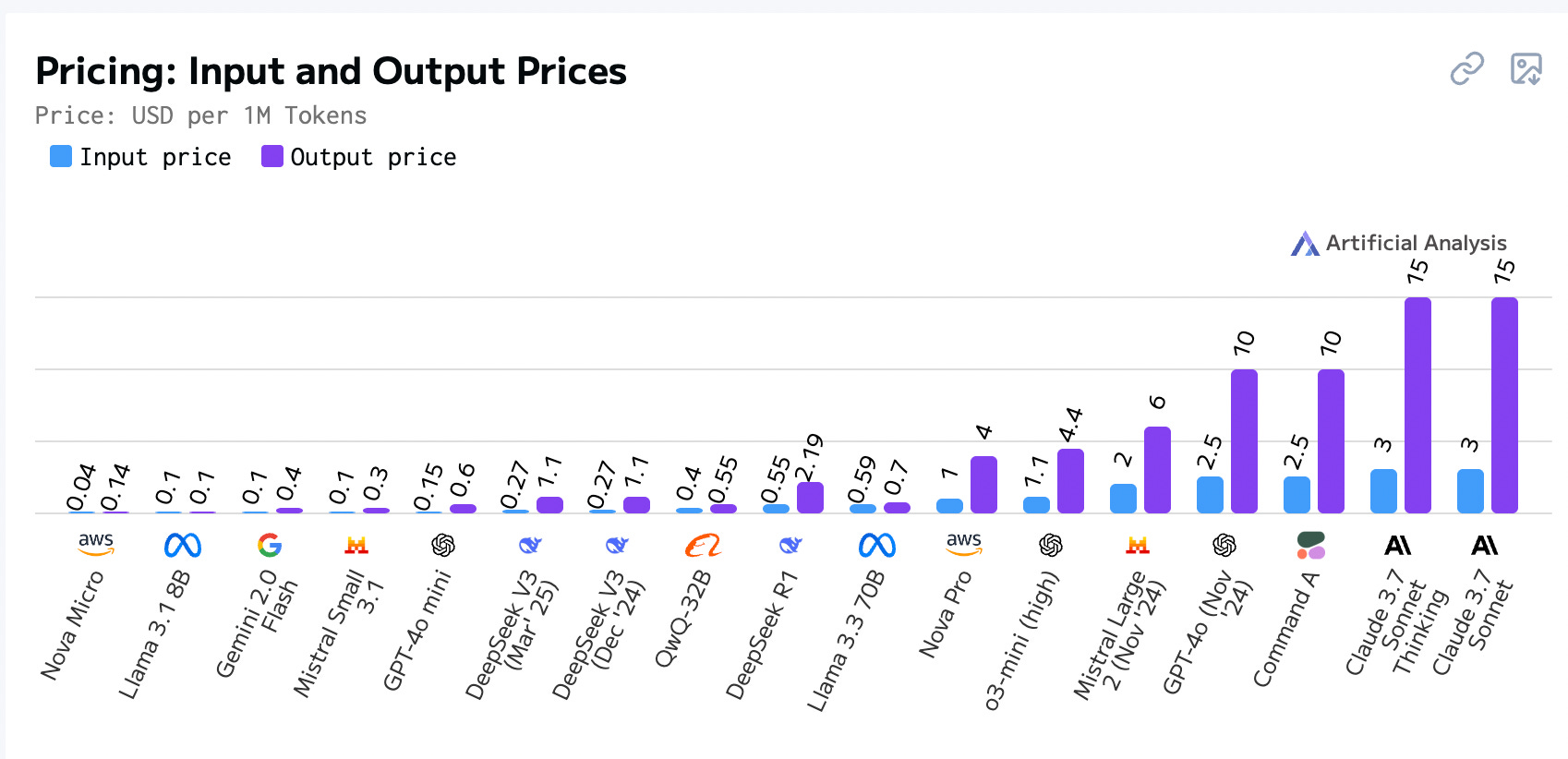
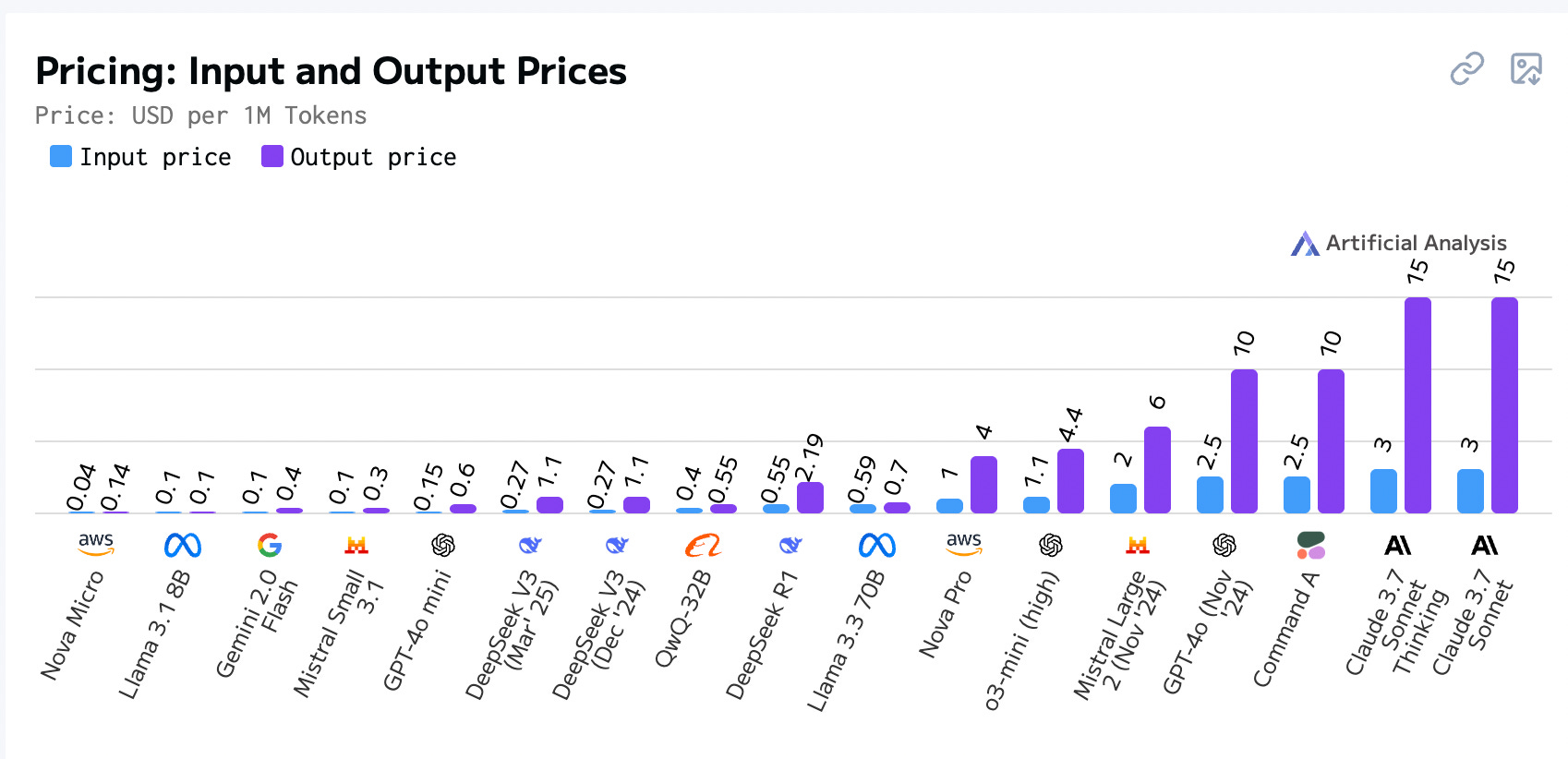
In SugarWOD the only way to mark WOD as scaled is via notes. Notice how everyone wrote 155#, 145 lb, 165lb, @165, etc.
Ok, so what’s the problem?
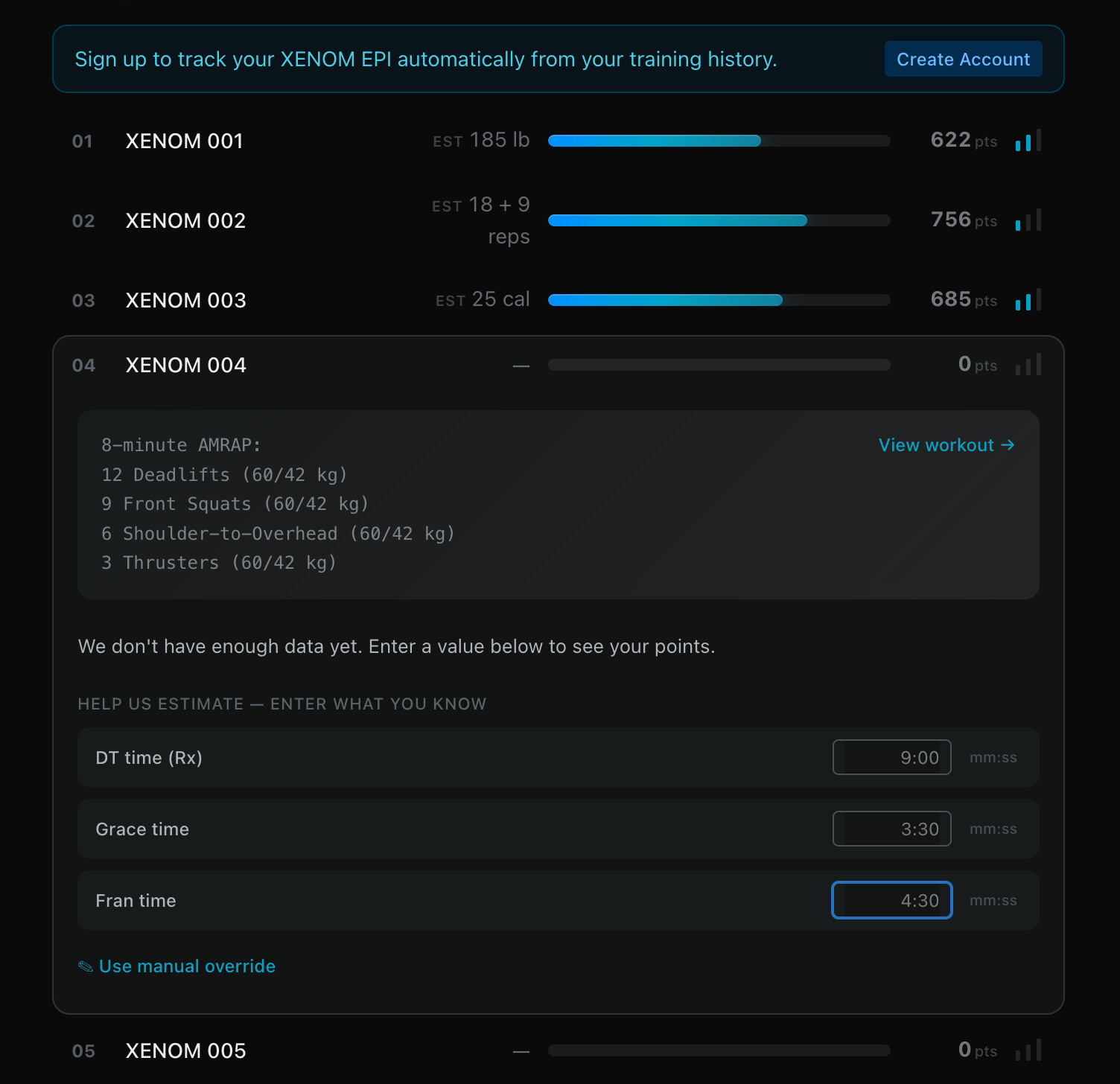
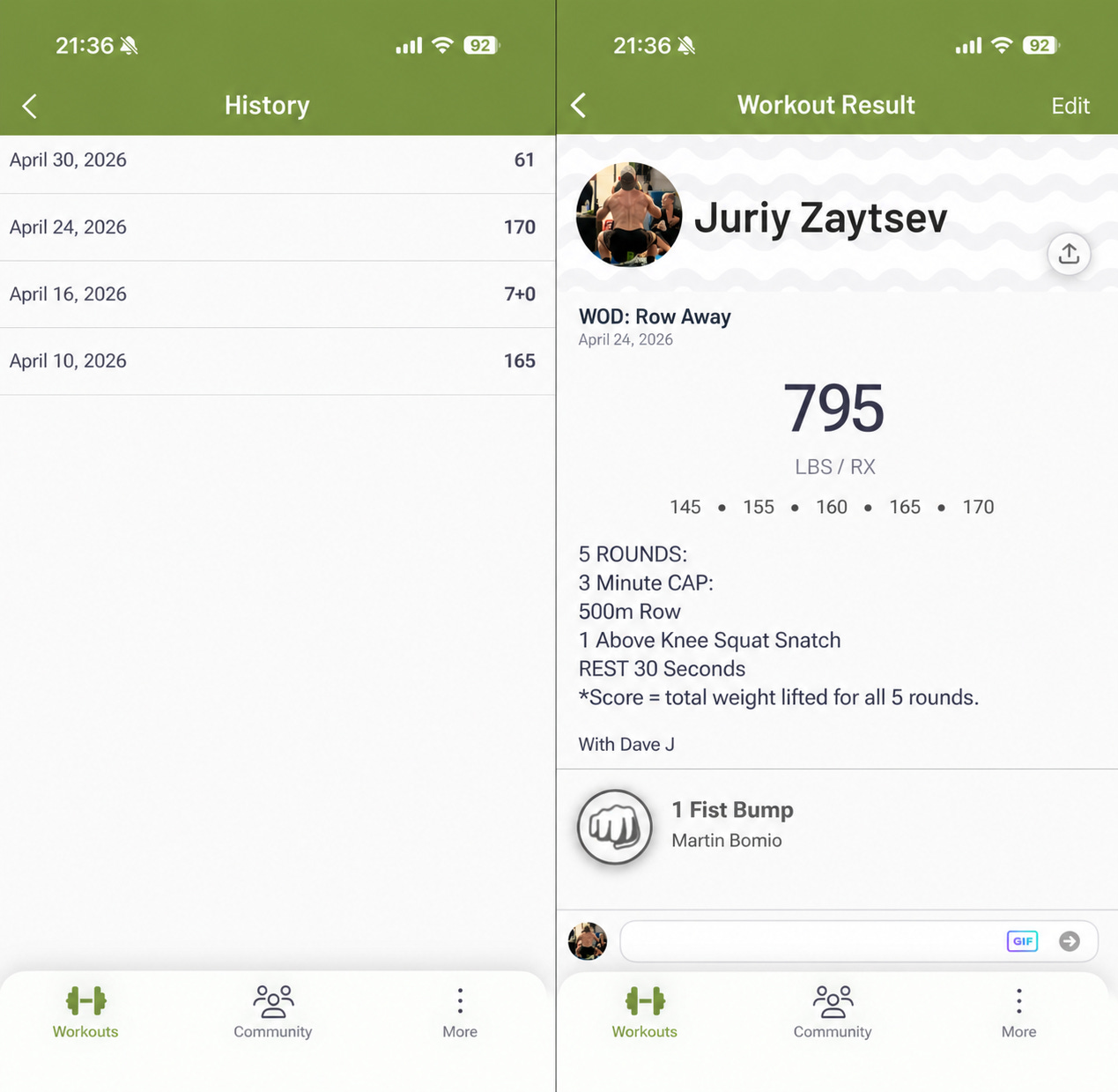
Well, the reality is that I’ve done 10 sets of 2 power cleans + 1 power jerk @165lb. My training log in SugarWOD, however, has no idea that this is what I’ve done. If I go into “History” for this WOD and click on Apr 24 I see “170” which makes me think that maybe that’s the previous weight I did. But no, it brings me to a WOD where I did “1 above knee squat snatch @170lb” not “2 Power Clean + 1 Split Jerk” or even just “Power Clean + Split Jerk” or even just a standalone “Power Clean” / “Split Jerk”:
It’s entirely wrong and confusing. And if I go into my barbell lift history, this weight I just lifted is neither under Power Clean, nor under Clean and Jerk, nor under Split Jerk:
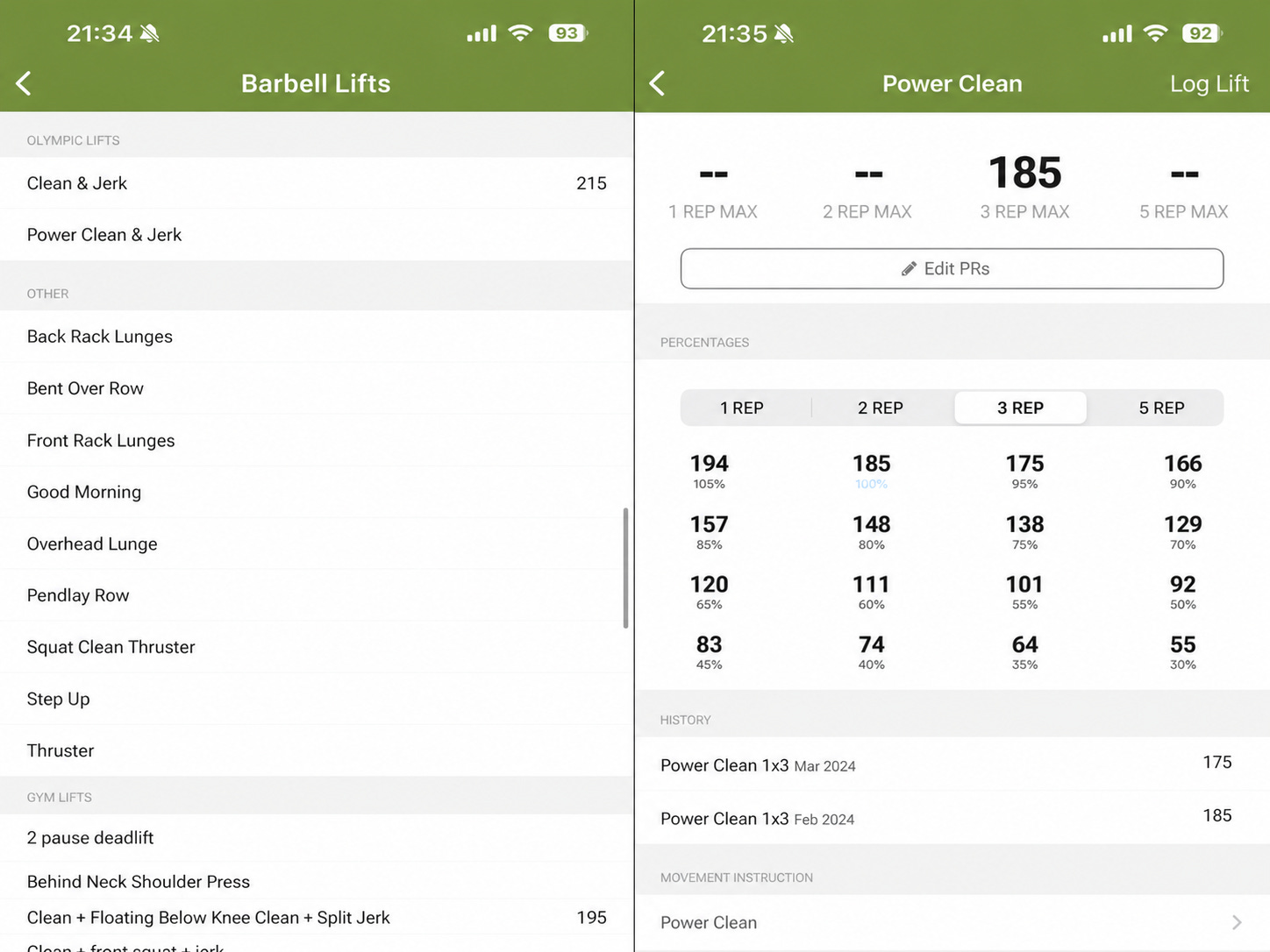
The two lonely logs for Power Clean are from Mar 2024. That’s… 2 years ago. SugarWOD has no idea about countless times I’ve done power clean in a WOD like today.
My barbell PR history in an app simply can’t be trusted.
Ok, that’s SugarWOD. What about others? Of ~25 apps, only BTWB and WodUp treat scaled work as structured data — and both punt on the hard part. BTWB excludes scaled metcons from its fitness rating. WodUp tags them four ways but disqualifies any scaled benchmark from PR tracking. Everyone else — Wodify, SugarWOD, Mayhem, CompTrain, TrainHeroic, Hevy, Strong, the long tail — collapses your work into Rx/Scaled + a score + a notes field.
Thanks for reading Juriy’s Substack! Subscribe for free to receive new posts and support my work.
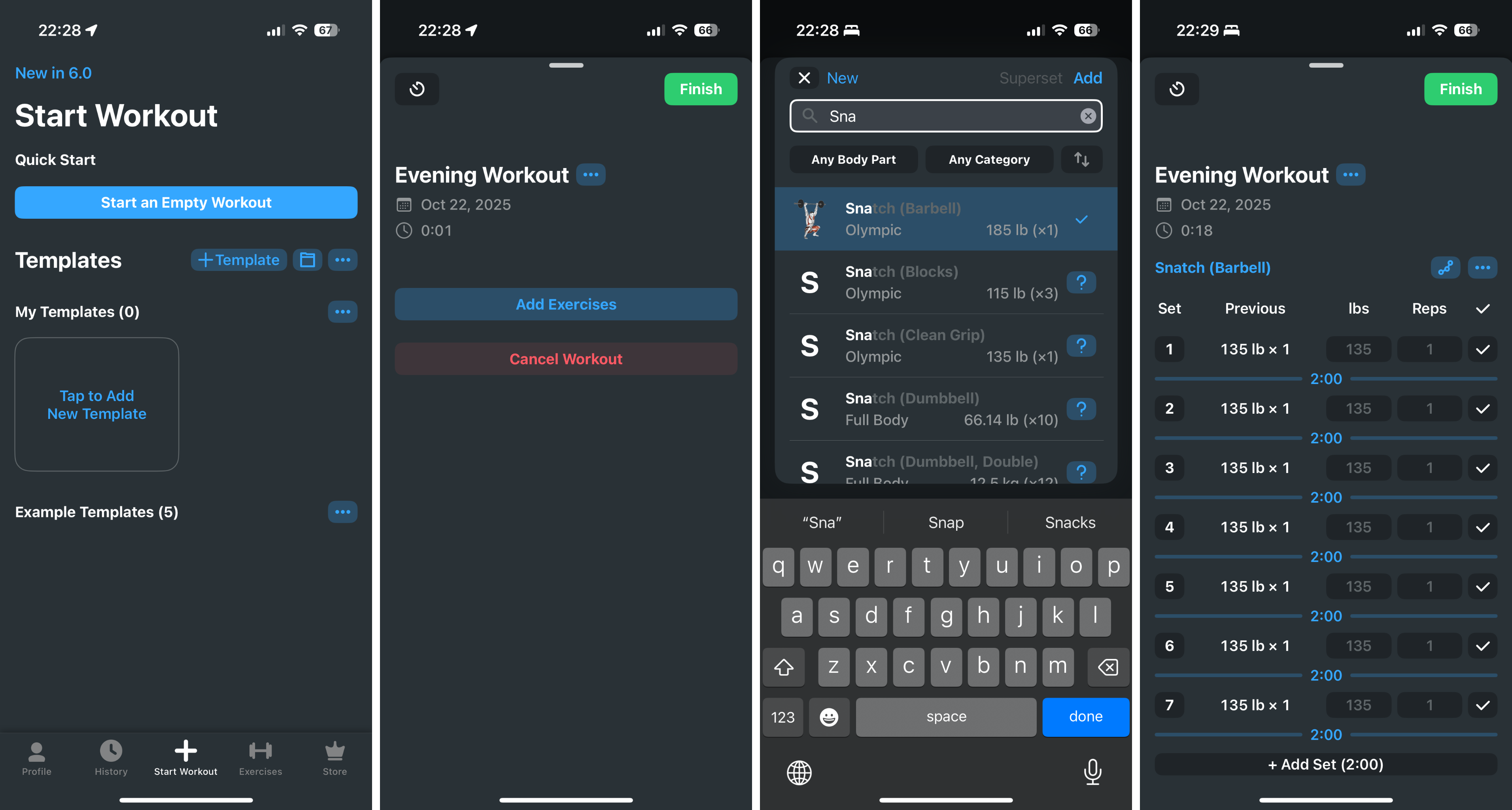
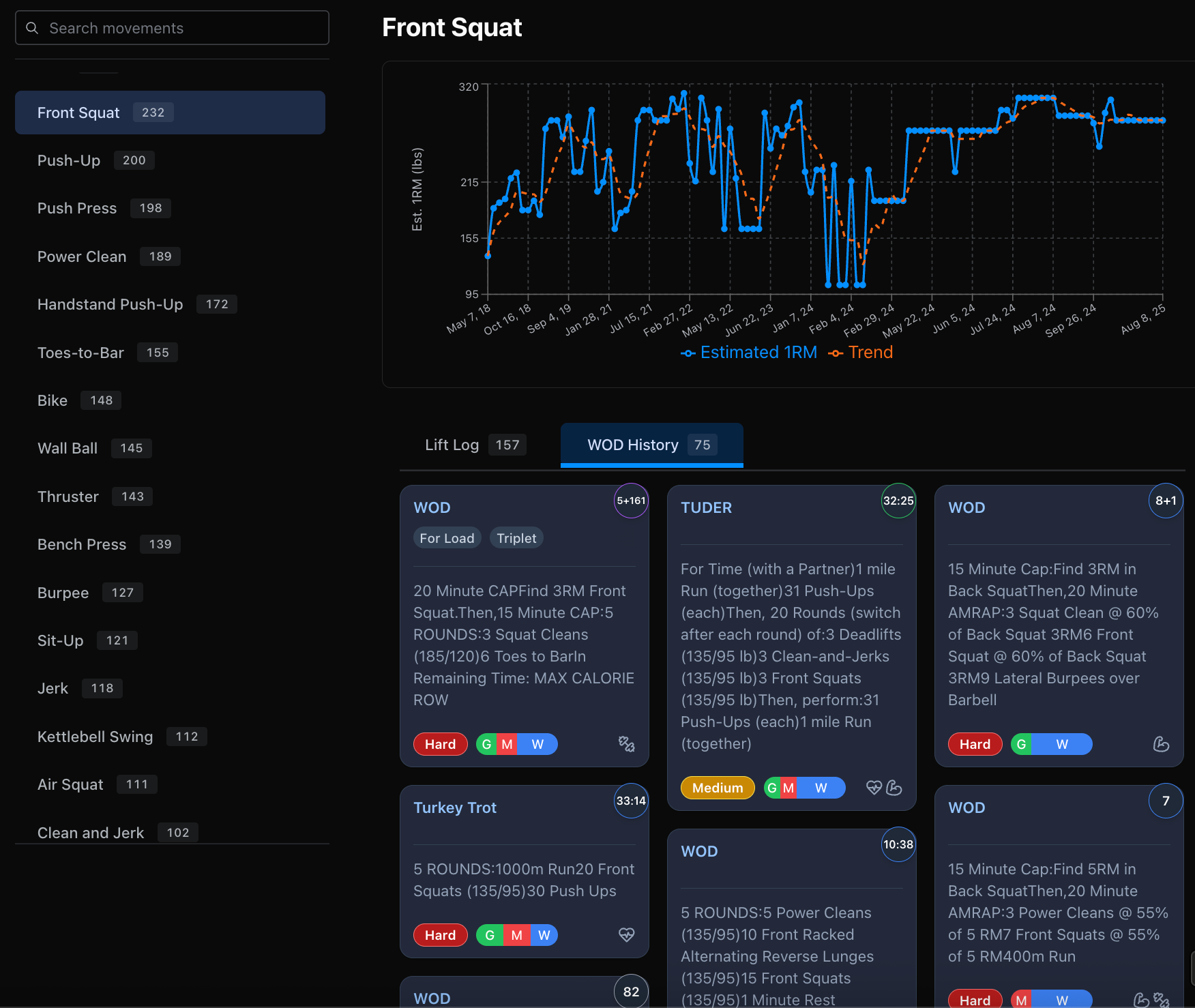
We were already half-rightIn PRzilla, we already tracked all movements correctly when logged individually or as part of a WOD. Here’s a workout with Power Clean that I did in Apr 2025 which SugarWOD never showed. It’s displayed in the history, alongside individual lifts:
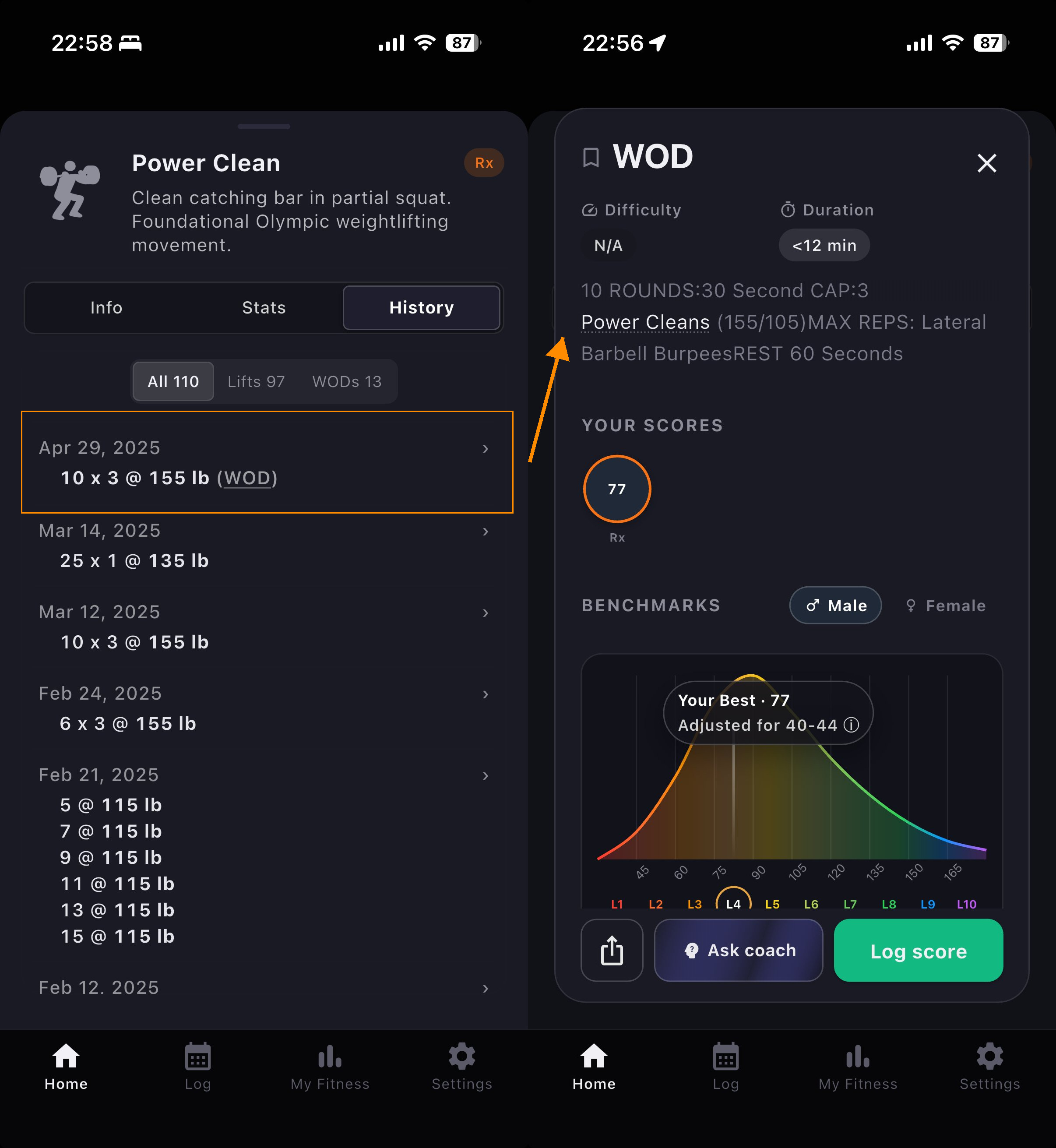
Scaled WODs like this Holleyman were part of the history too, but we didn’t actually know how you scaled them outside of the notes. It would just display as "(scaled)” and not be part of any metrics:
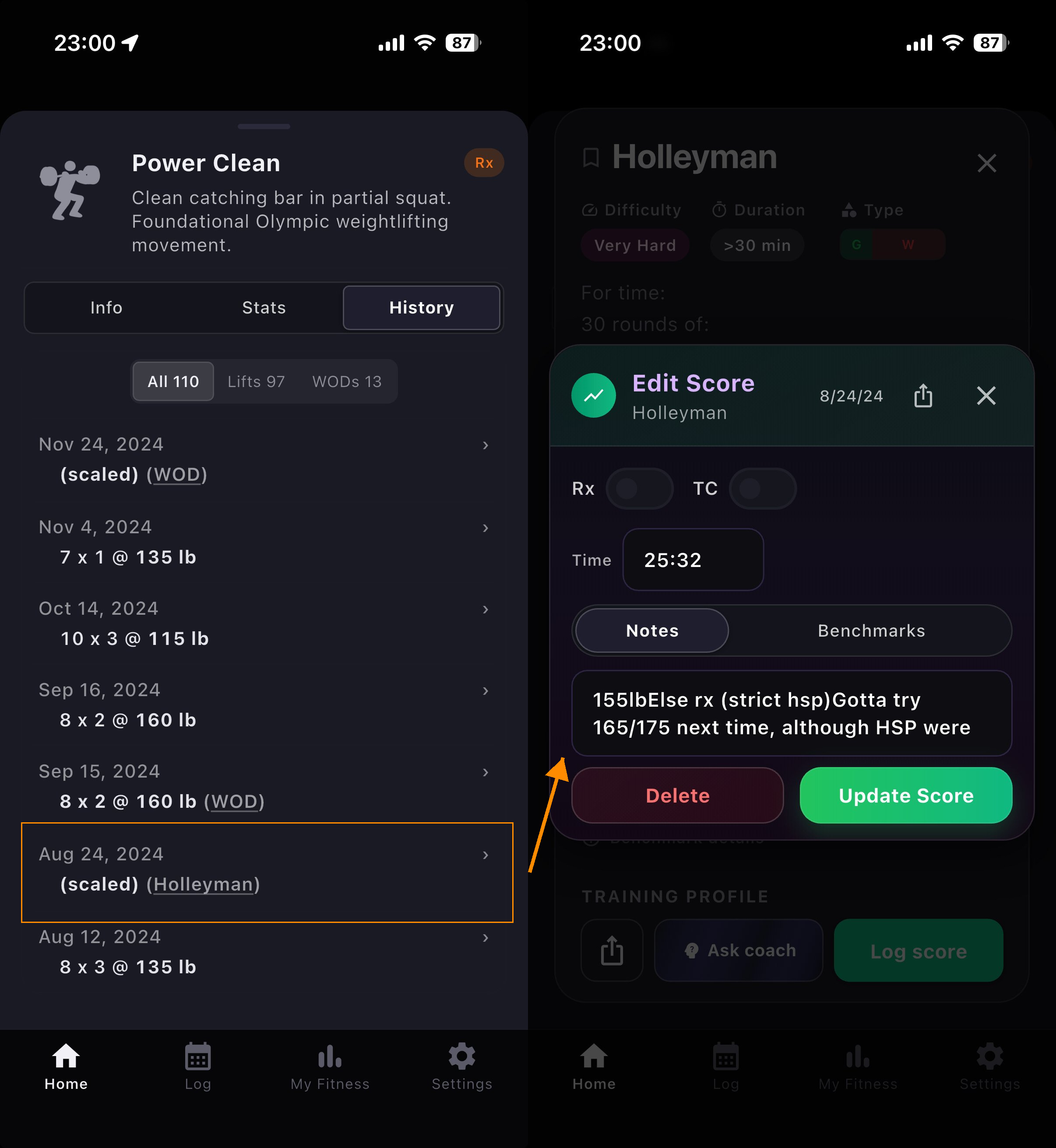
I always knew this is one of the most important things to have in a CrossFit app worth its salt; after many weeks of work, it’s finally here.
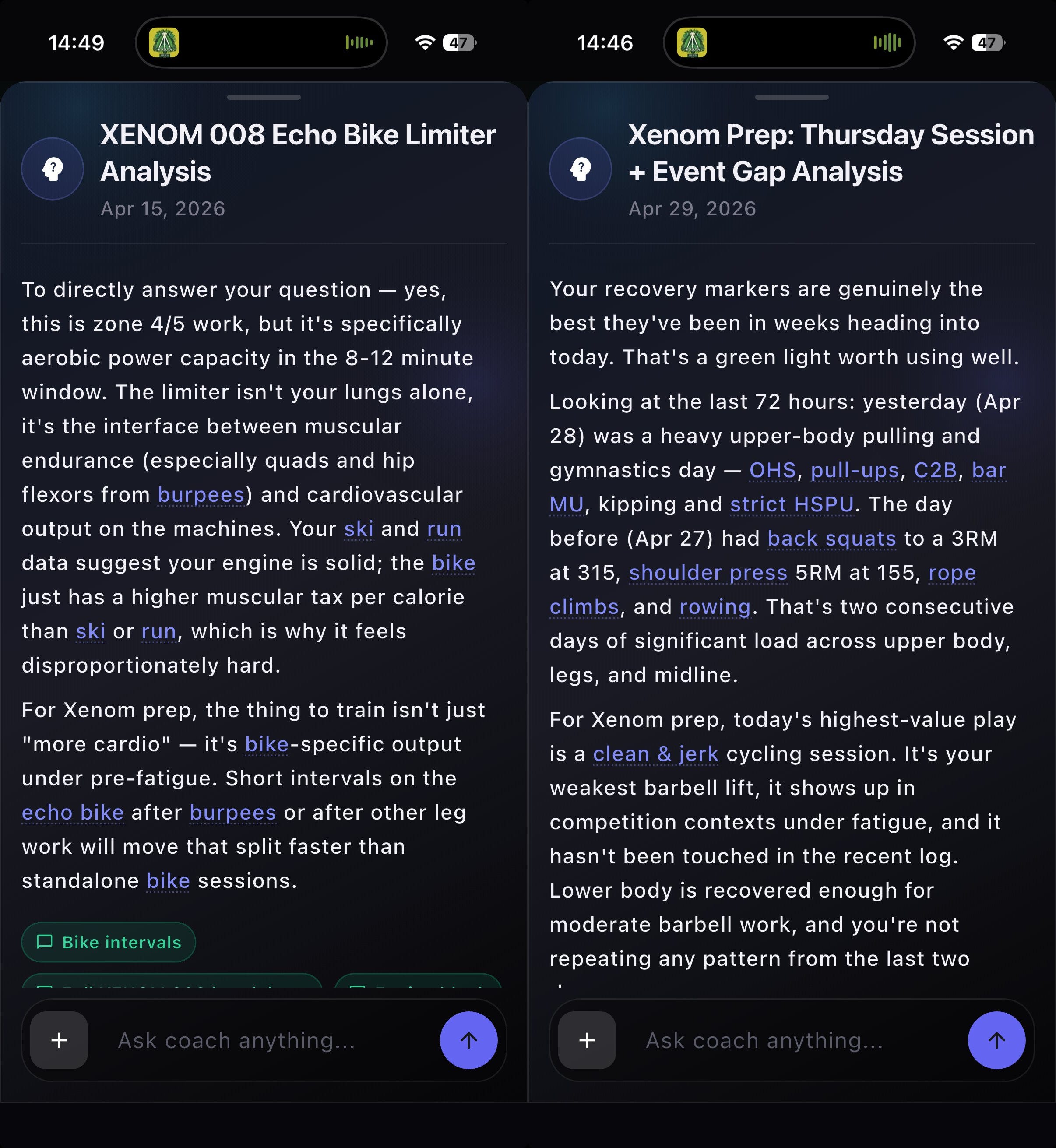
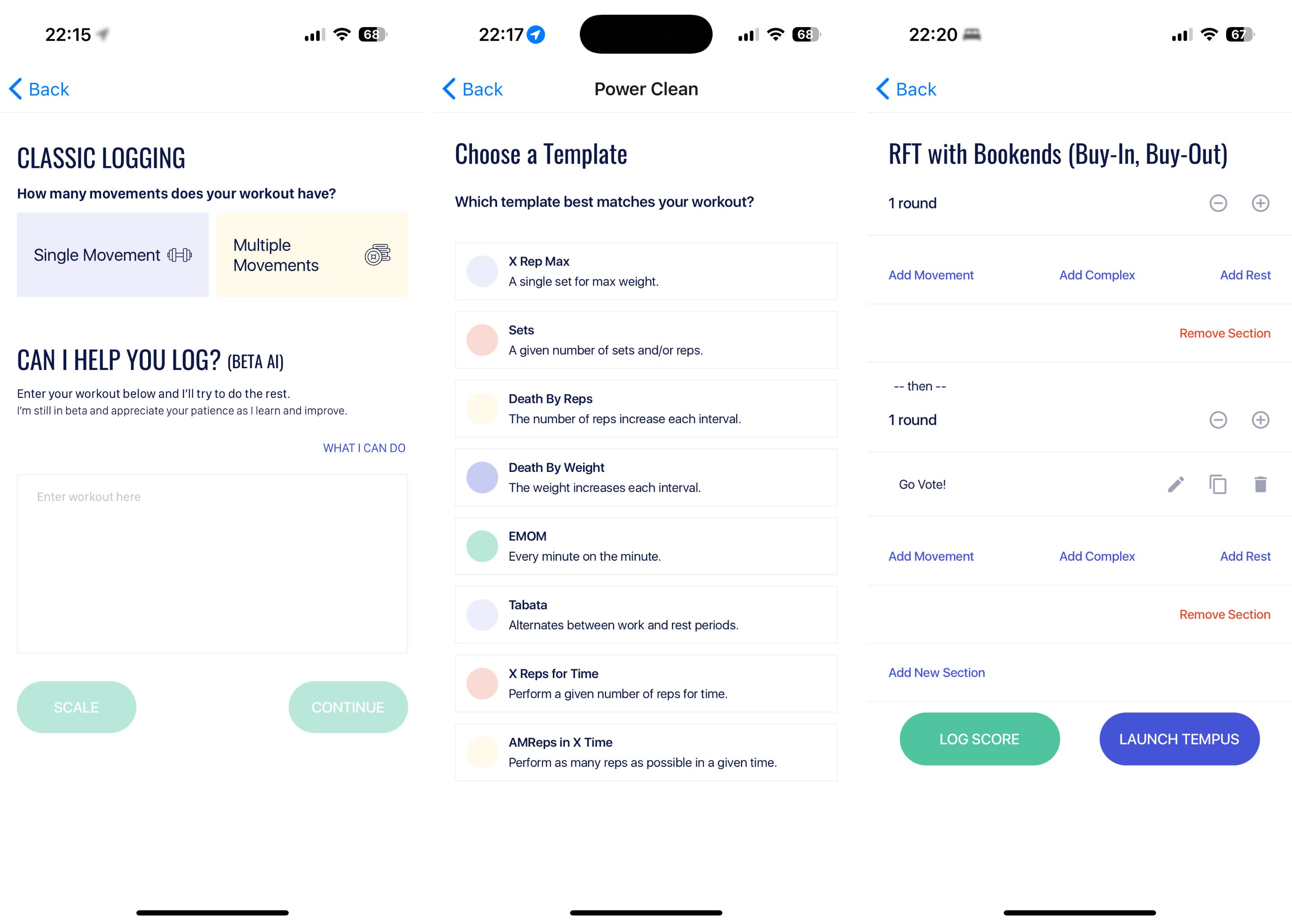
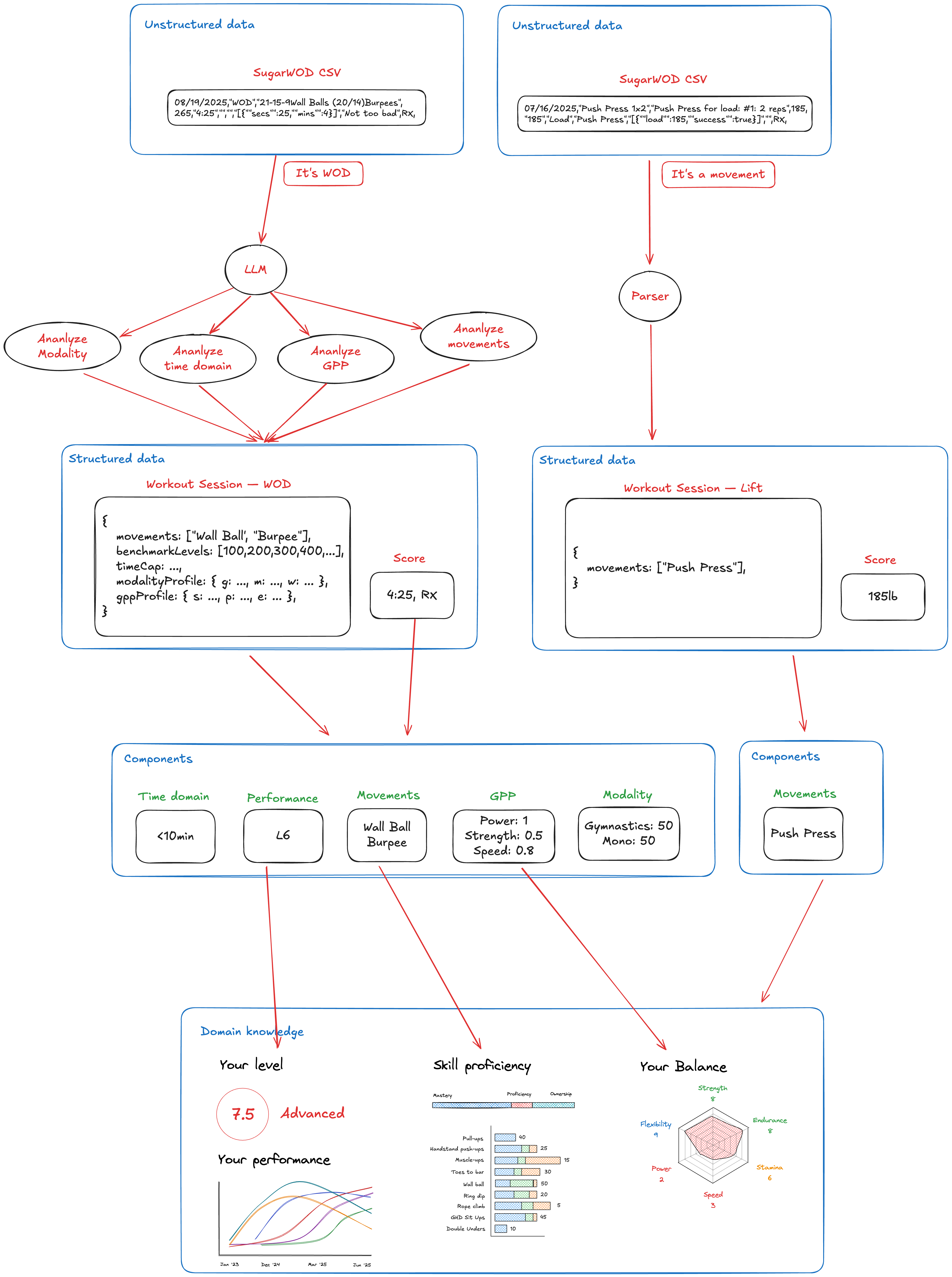
You can now specify exactly the work you’ve done when logging any WOD in PRzilla. WOD’s are just prescriptions. Every WOD is decomposed into movement blocks. And it’s those movement blocks that define your history, stats, charts, etc. in our system.
But here’s a harsh truth: the last thing athletes want to do when logging WODs is to spend few minutes tinkering with movements, sets, reps, and weights. Sweaty hands. Still breathing hard. 99% of us write “165#” and move on. That’s why it was very important for me to remove as much friction when logging scaled WODs as possible.
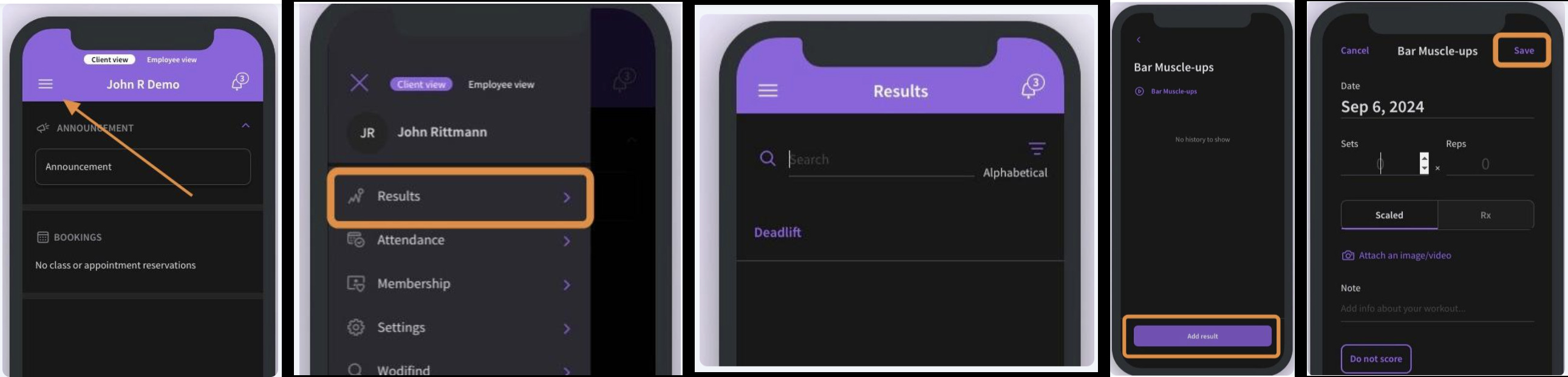
Let’s go back to the Clean & Jerk WOD. The moment I add it, PRzilla parses it into Power Clean, Split Jerk, and Air Bike; it creates all 10 sets of each, prefills first with 2 reps, second with 1 rep, and adds RX weight to both.
Because I scaled to 165lb, all I need to do is type “165” in Power Clean’s topmost weight cell and click “Apply to all sets below”. It takes me the same amount of time as writing “165#”.
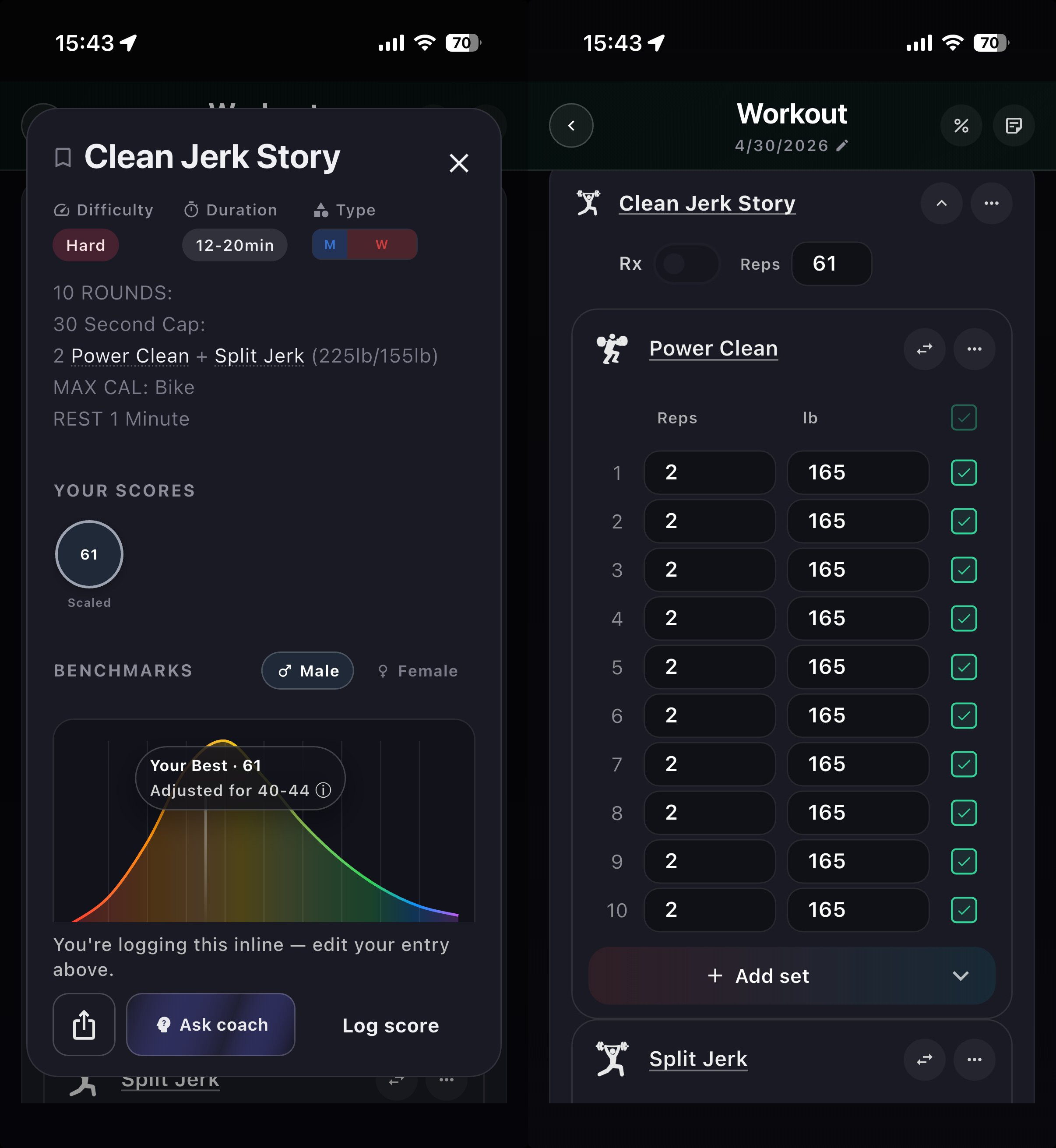
If I scaled that WOD to just power clean I can remove Split Jerk movement from the session by clicking “Delete”. It’s actually faster than typing “Did not do Split Jerk” in the notes. And I can replace power clean with dumbbell clean just as quickly as typing “Scaled to db cleans”.
We now have the power of a full-blown workout editor within the context of one WOD. And we have minimal friction.
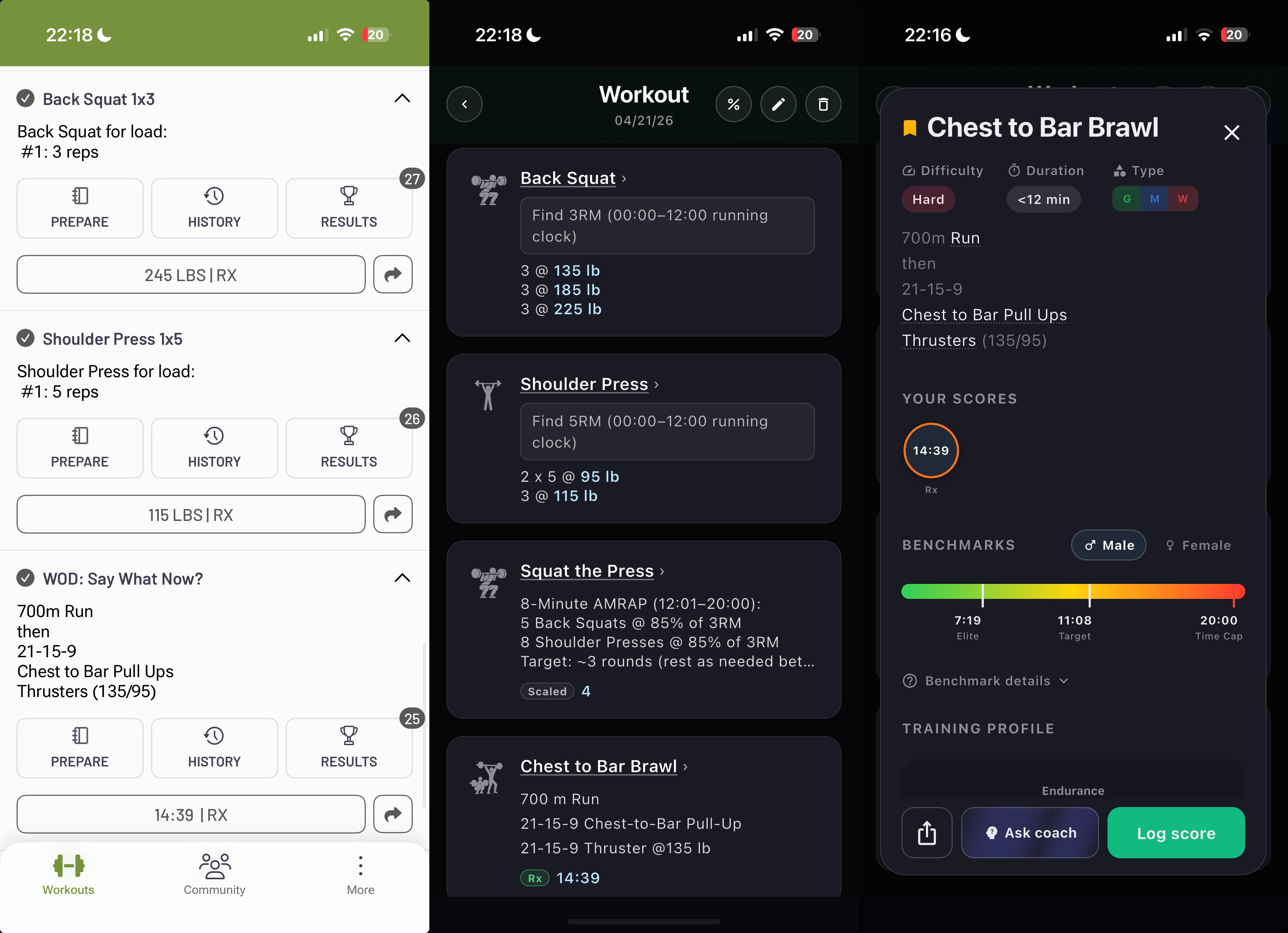
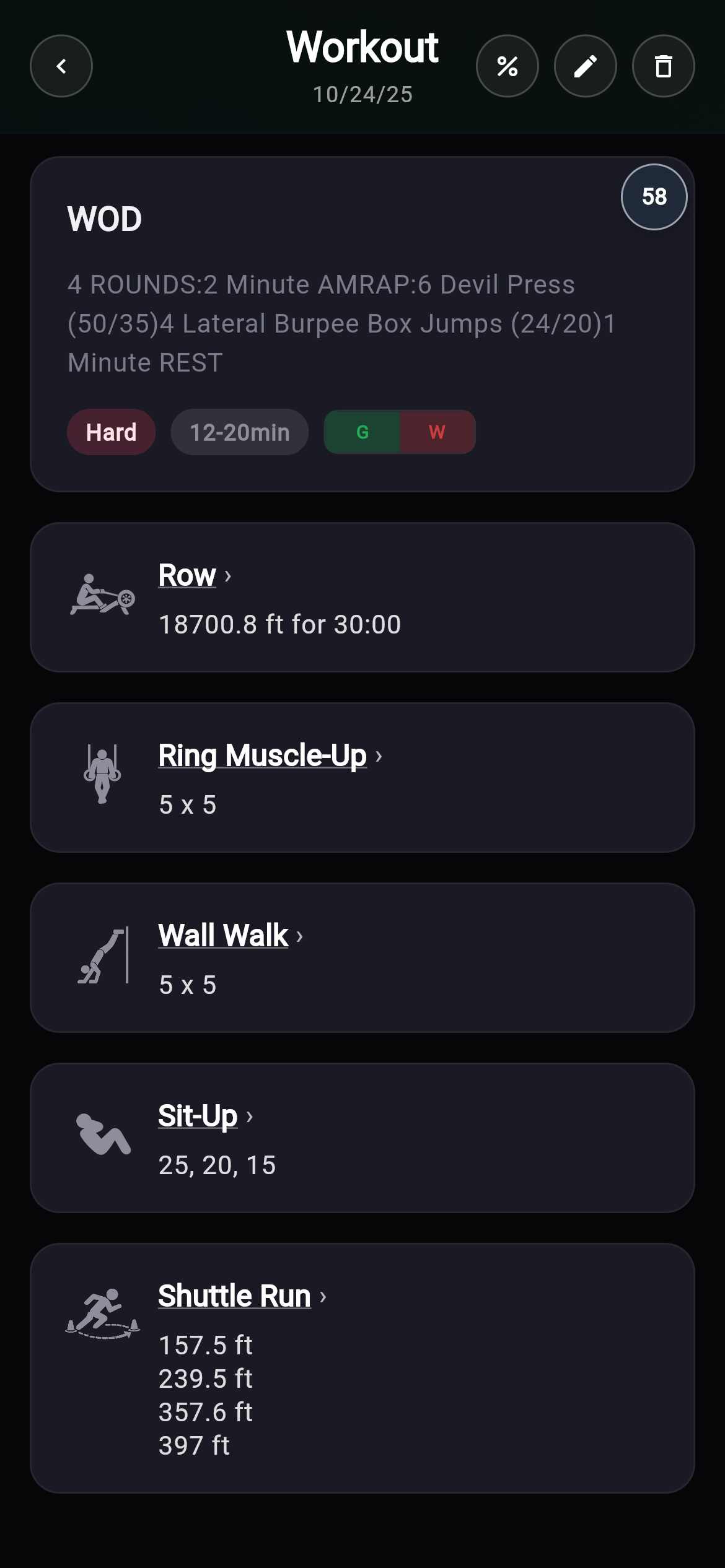
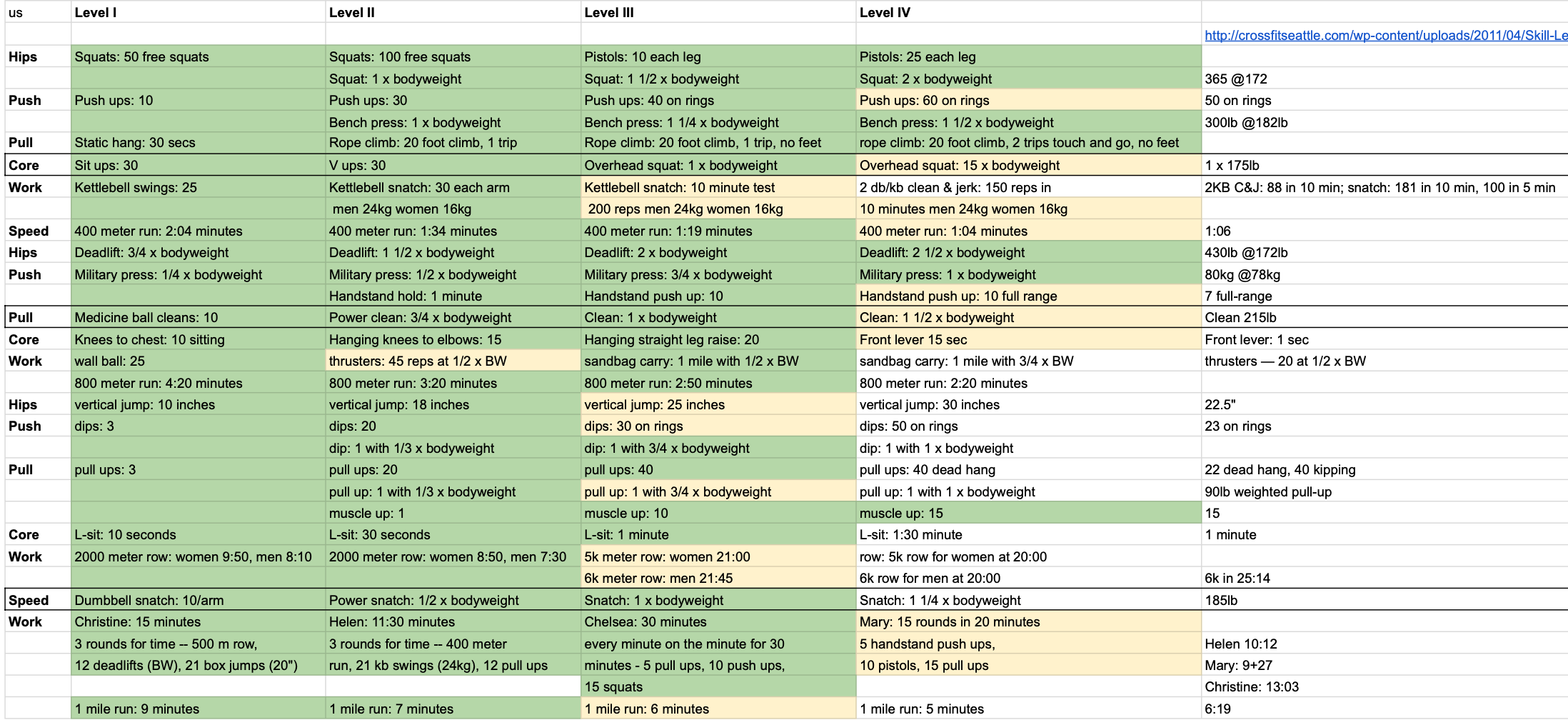
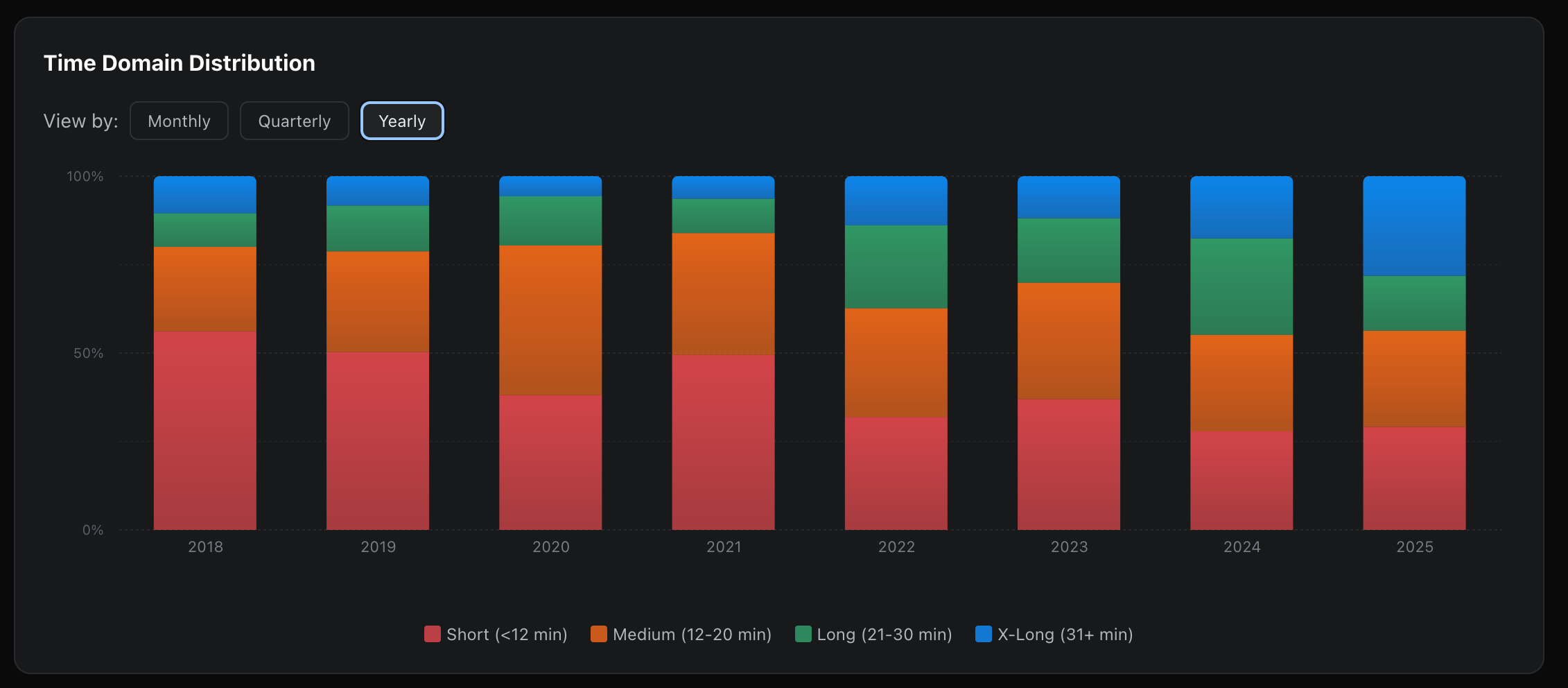
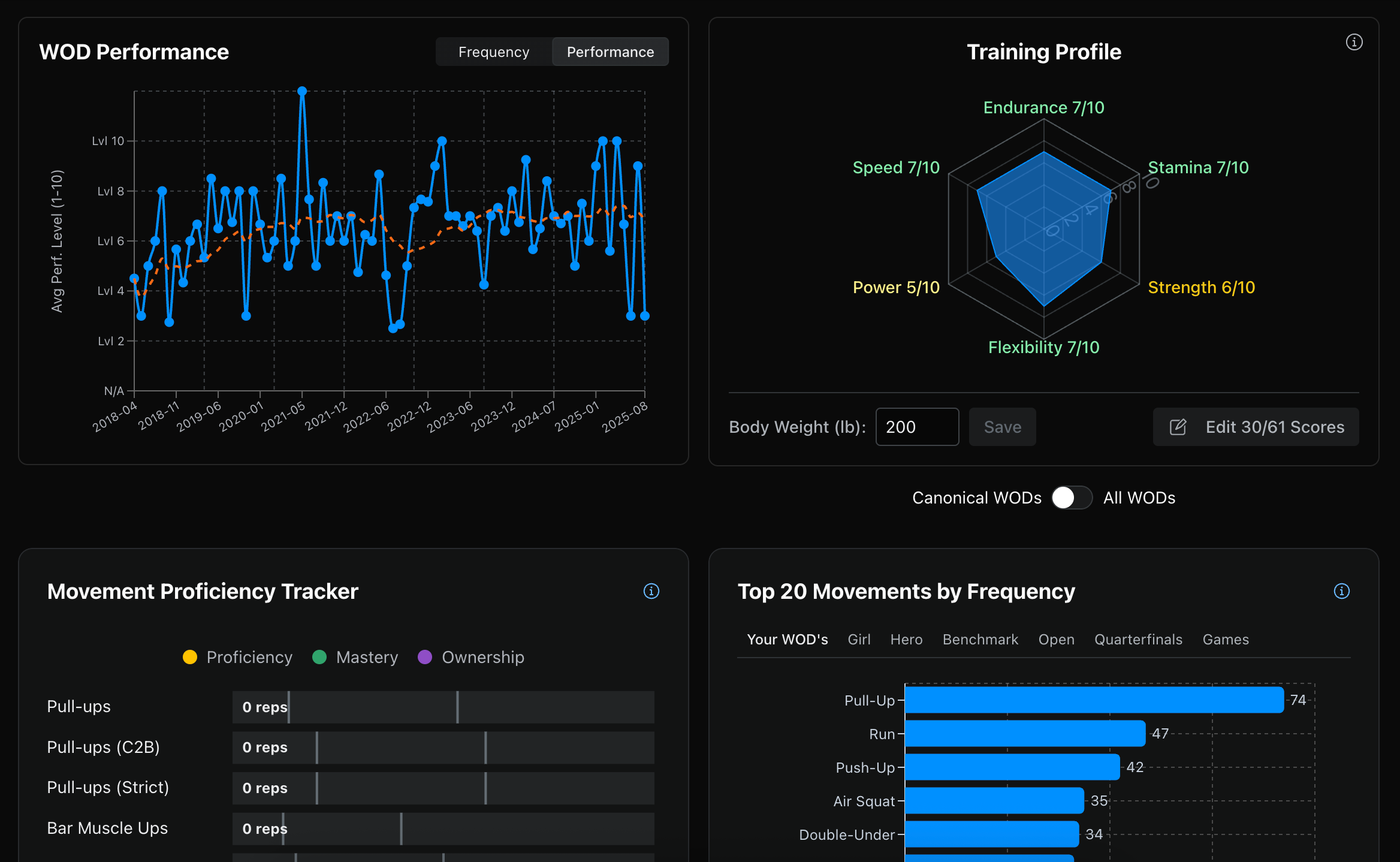
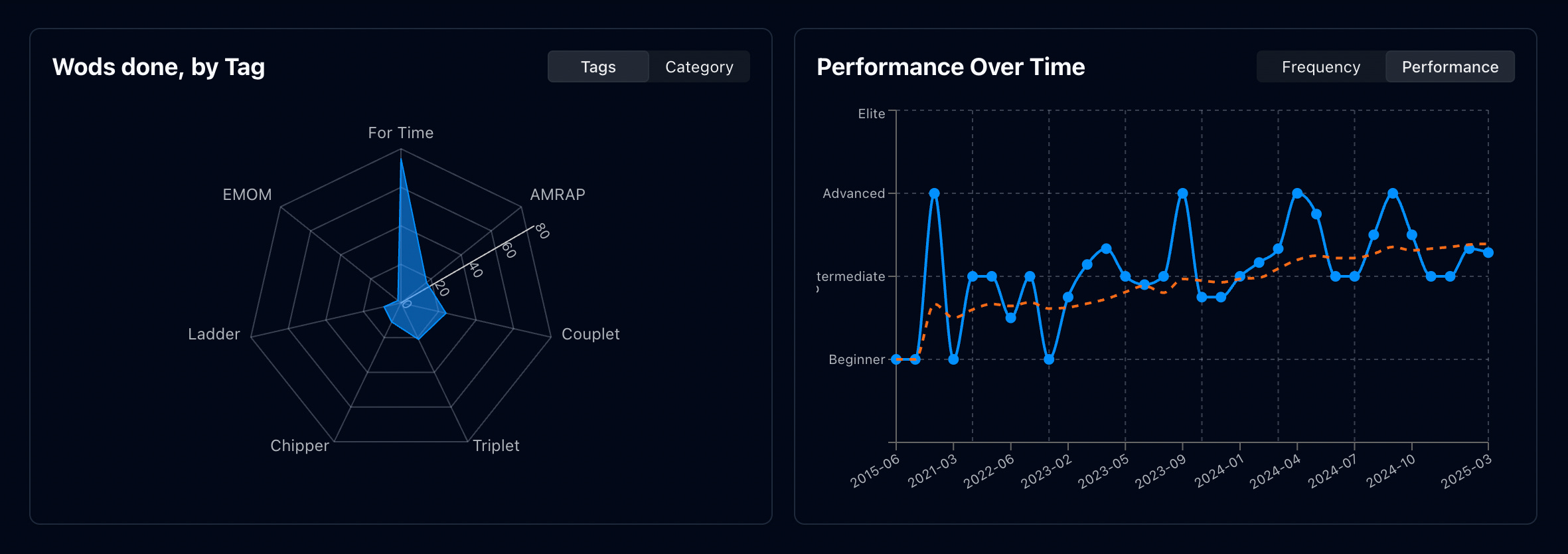
From score to signalWhen looking at your workout session (left pic), you now see the things you’ve actually done and not just what was prescribed. A lot more useful metric that goes in line with the rest of the movements in a workout session. After all, we show 3 x 2 @ 275lb on Front Squats and not just “Find 2RM in 15min”:
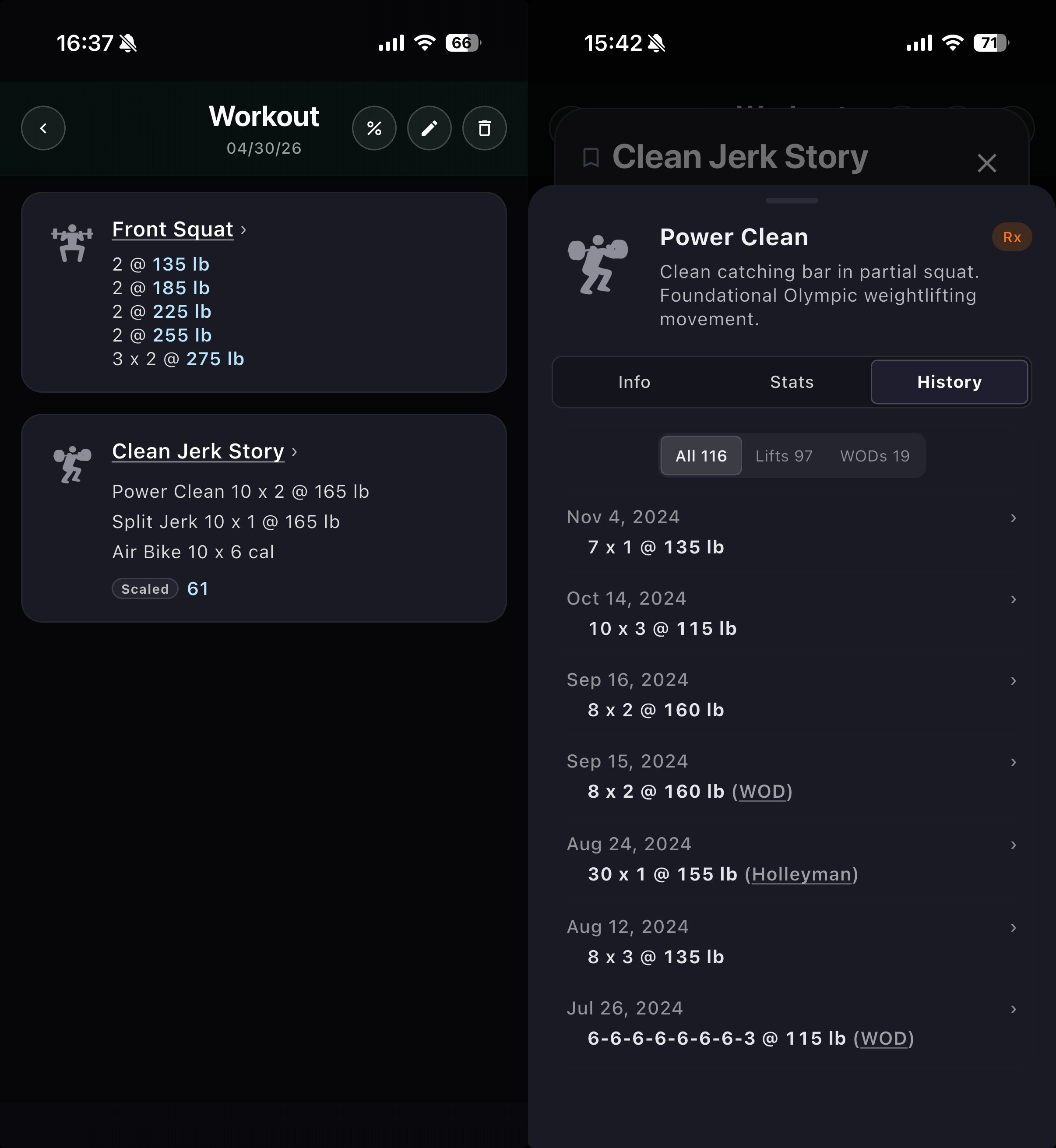
The Holleyman (right pic) is now displaying 30 x 1 @155lb because we have your actual weight as part of the WOD movements (=work performed). Seeing all the weights in a history list like this feels like a basic right in a CrossFit-aware workout tracker :)
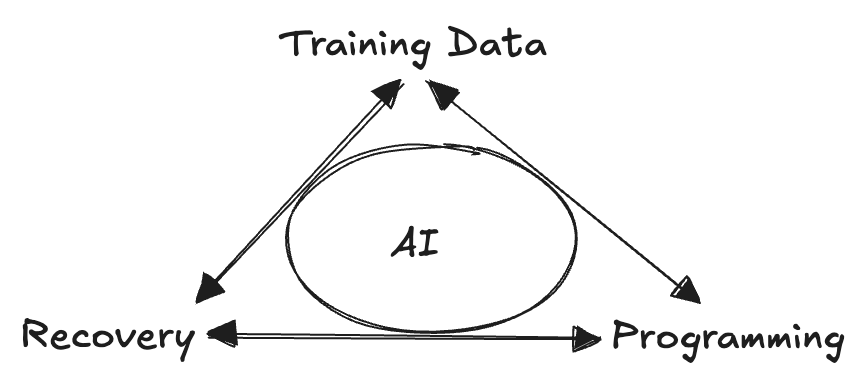
Ok, charts and history lists are nice and all but… does this all really matter? I think so. Accurate training data is the foundation of your fitness training. We need to know where you stand in order to design a path forward.
If you scaled Holleyman to 185lb (and finished all 30 rounds), now we know these things:
1RM — this tells us that your max is at least 185lb without explicitly testing it.
1RM is essential for daily programming.Volume — you’ve done 185x30=5550lb of Power Clean in that session.
When we know your volume, we know the intensity of a given workout relative to your usual effort. If you’ve only ever done 1000lb of power cleans in a WOD, doing a WOD with 5000lb will wreck you for days. We can mark such WOD as high-volume for your level. A high-volume day can then either be scaled correctly or programmed in a way that doesn’t interfere with other workouts in a week.Progress — Holleyman @155lb in 20min vs. Holleyman @185lb in 20min is the kind of progress you can see if we track scaled work. That’s density: more work done in the same amount of time. It’s important to know if you’re trending up, down or plateauing.
Programming — passing your results to AI coach makes for highly relevant advice. If it knows you did 30 rounds of power cleans @185lb, it can use that to create a workout that’s within your reach. It can tell you to scale up or down next time according to this weight. It can even flag less obvious things like weak squat clean in relation to power clean.
A coach who doesn't know what you lifted can't tell you what to lift tomorrow. Neither can your app. PRzilla is my attempt to fix that — give it a try.