Show full content

One afternoon, I was asked to speak to a visiting class of engineering students about what it was like to be an engineer. I found myself in an open meeting space in our office (remember when we met in offices?) surrounded by kids in their late teens and early twenties. I was not sure what to say. My coworkers seemed confident, so I pretended to be too. I figured I could tell them something valuable about my experience that they could take away, maybe something they did not already know that would spark their interest in a similar career. I did not expect they would change me. They caught me off guard and blew me away with their questions and stories about their school projects. Their eloquence was extraordinary, and their questions were on point, sharp, and articulate. Their maturity was impressive; I certainly did not think and talk like that when I was their age.
That night ended filled with emotions. I was inspired and hopeful for the future of our industry. My heart was racing, and I was so happy that I had been pulled into the meetup. It would take another year before I collaborated for the first time with The Marcy Lab School. Those students, the first cohort to graduate from the Marcy program, will always remain dear in my memory. They, however, were not an exception. Every group to graduate from this alternative school is as remarkable as the previous, if not more.
What is The Marcy Lab School?The Marcy Lab School is “an alternative to traditional higher education for students who face financial barriers or for those who are simply looking for a unique experience better suited to their interests,” offering tuition-free instruction for high-achieving young adults from underserved backgrounds to prepare them for careers in software engineering.
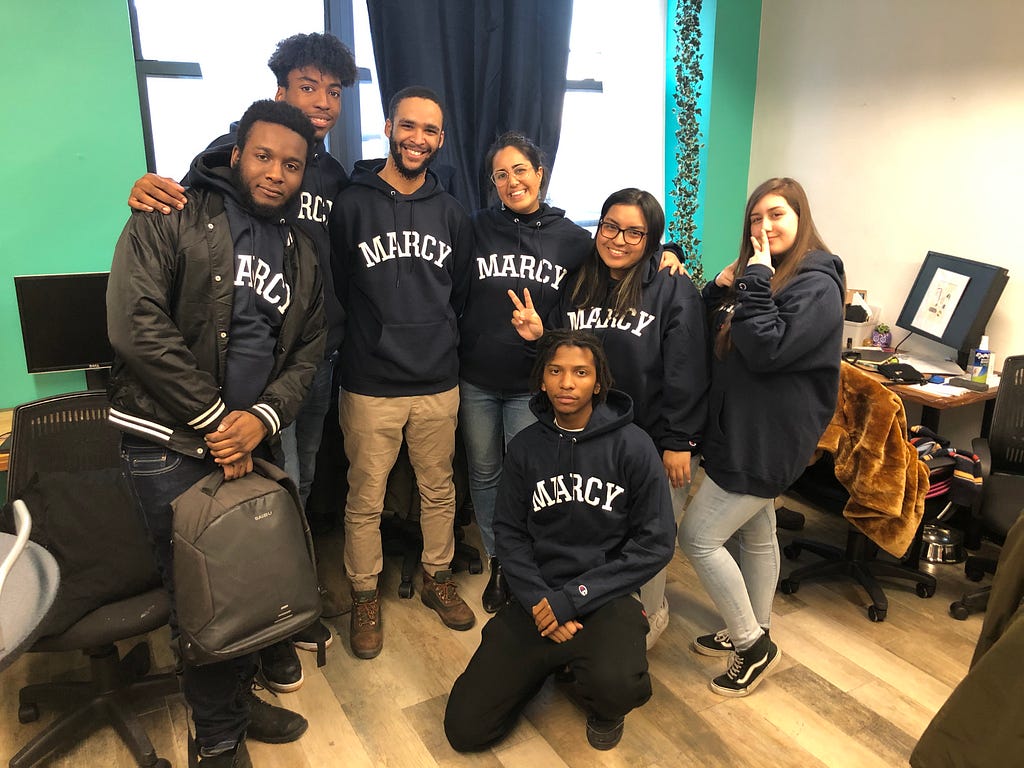
What this means for students is the opportunity to graduate debt-free and go on to make over $100K a year, working with companies that collaborate with Marcy to improve their curriculums and provide internships, apprenticeships, and direct-to-hire opportunities. They get a top-notch education without paying a cent — an education tailored to their needs, their interests, and the opportunities they will have upon graduation.
The Marcy mission is “to create an alternative pathway to wealth-generating technology careers for young adults from underestimated backgrounds.” They achieve this by leaving no student behind and providing an amazing student-to-teacher/mentor ratio, offering a ratio of 1:20 vs. the 1:5000 average of public college computer science programs. The classes are small, and the study groups are even smaller. They leverage peer-to-peer mentorship, with more senior students paired with newer ones. It is common to see Marcy graduates paying forward this opportunity as volunteers, mentors, and teachers. Those who struggle with concepts or practice get more attention, not less (like they might in a traditional college). With this strategy, they help everyone realize their potential.
The Marcy Lab School curriculum is far from a boot camp format. They divide the day for their fellows into engineering classes, labs, and leadership and workforce readiness classes. They go deep into computer science essentials that you could find in CS classes at a traditional college, then apply that to tools we use in our day-to-day engineering tasks at our Xandr offices (and probably yours, too).
The co-founders, Reuben Ogbonna and Maya Bhattacharjee-Marcantonio, are inspiring. You talk to them and are immediately drawn to their energy and the culture they’ve created at the school. Reuben and Maya were teachers who got fed up with the state of education, its level of support, and the economics of the overall educational system. So they set out to change it. Now they have an equally passionate supporting staff and an inspiring student body.
As an engineering lead, I often think about the meaning of equity and inclusion. Not as labels and figures to meet our annual goals, but as true measures of creativity and ingenuity. Working with Marcy means reaching into a diverse pool of engineers that are ready to pay forward the opportunities they found through the school’s program. We want to help the school expand, and then continue its mission by bringing their fellows into the workforce of a company that values many of the same principles.
Our volunteersXandr, part of Microsoft Advertising, has embraced the value of giving back through donations and volunteering. Microsoft has a long history of philanthropy, reflected in its mission “to empower every person and every organization on the planet to achieve more.” Through its corporate matching program, Microsoft matches employee time and money to help others advance, fighting financial and racial inequality. Our company’s values align with Marcy’s mission. Our people’s values do, too.
At Xandr, we have a “teach and learn” culture because we understand that a great way to learn is by teaching others. We believe in giving people time to absorb the complexities of our systems and business when they join us and asking them to teach their learnings back to the group, often improving our own onboarding materials. This process is similar to how Marcy works with their fellows, listening to their graduates to adapt their curriculum to the changing needs of the tech world.
It is only fitting that our teach-and-learn culture would make us a great candidate to have a strong partnership with Marcy. Earlier this year, we became a sponsor for Marcy’s Summer Social, where we joined them in celebrating the graduation of their 2021 cohort. There our love affair started, and we hit the ground running. We arranged for a group of volunteers from our engineering organization and other groups in the company to become mentors to the Marcy Fellows.
Each of our volunteers donates their time by meeting with a student throughout the school year, helping them navigate the hurdles of becoming an engineer ready to join the workforce. Some of them will also help during the interview process to select future cohorts. They also hold mock interviews, where current students can face technical and cultural panels in preparation for their job search.
Our volunteers do this because they care. It’s the same care that drives The Marcy Lab School, and the reason why equity and inclusion are important. We should care about everyone and take action to lift them up in ways that inspire them to lift others in turn.
For us, this is just the beginning. The partnership between Xandr and Marcy Lab is off to a great start, and we hope to add more volunteers next year. If what I’ve said resonates with you, know that you can help with very little time or money, and that your volunteer efforts could positively shape the future of our industry. I go back to that afternoon in my office’s kitchen often, and I hope that those incredible graduates are in some of your offices today, adding value, being amazing human beings, and changing the culture of engineering for good. I’m proud to have known them, and I’m excited to see what each subsequent cohort will bring to our industry.
Xandr and The Marcy Lab School was originally published in Xandr-Tech on Medium, where people are continuing the conversation by highlighting and responding to this story.