Show full content
What connects these three seemingly separate stories, besides tremendous damage to the involved individuals?
In 2016, Wells Fargo was found to have created millions of fraudulent savings and checking accounts without their clients' consent, resulting in fines of $185 million. The scandal has had ongoing legal, financial, and reputational consequences for the company and former executives, with additional suits totaling an estimated $2.7 billion.
In March 2019, the grounding of Boeing 737 MAX 8 and MAX 9 aircraft was instituted in over 41 countries, including the United States, Canada, and China, following a deadly crash involving an Ethiopian Airlines plane. This was the second crash of its kind involving a Boeing 737 MAX, resulting in the deaths of all passengers.
In November 2022, the crypto exchange FTX collapsed in a dramatic fashion after Binance's CEO Changpeng Zhao tweeted that he was planning to sell off Binance's holdings of FTT (FTX's token), which caused FTT to fall rapidly, triggering a liquidity crunch, suspended withdrawals, investigations, realisations and, eventually, bankruptcy.


One common thread in the above stories, and in many stories similar to these, is the main characters' fixation on outcomes — lagging indicators of success — rather than inputs — the leading indicators of success.
What about some positive examples?Amazon is one of the largest and most well-known retail brands in existence, not to mention their cloud business. Regardless of what you may think about Amazon and its business practises, it's worth asking "How does an online bookstore startup end up as the foremost online retailer in the world?".
Is it possible that they have been tricking people into spending more money on stuff for nearly thirty years? Did they "succeed" by secretly charging customers' credit cards and shipping things to them?
No. Amazon got to where they are by relentlessly focussing on the customer's needs — finding out what customers care about and delivering it day in, day out, for decades.
In the investment world, where the majority of funds underperform the SP500, Warren Buffett focuses on the fundamentals and finding value, not making a quick buck or living off clients' fees. He does not care about looking foolish in the next quarter or year, because he knows that only by buying great businesses at good prices, over the long run, is the key to outperformance. He cares about beating the SP500. But he cares about buying great businesses more.
Would it have been possible for Warren Buffett to get rich — a lagging indicator of success — by prioritising extracting fees from clients? Sure. Nick Maggiulli argues that many hedge funds do, in fact, get rich that way. But to achieve the outsized success that Buffett has achieved with Berkshire Hathaway requires more than gouging fees until the next economic downturn or market crash. It requires prioritising not losing money for his clients.
What's this got to do with you?The examples above may seem like far-fetched scenarios that don't apply to us individually, but in each of the above instances there was an individual making decisions about what to measure and what to optimise for.
The concept of leading vs lagging success indicators boils down to inputs vs outputs and figuring out which inputs are effective for positively influencing the outputs.
Folks often take shortcuts by trying to improve the output directly — without investigating and testing which inputs give rise to them in a sustainable way. In the FTX example, SBF invested heavily in making it seem like FTX was a reputable crypto exchange, rather than making sure that it actually was one. These "shallow" shortcuts might work for a while in the short term, but reality has a way of erasing them — often quite painfully.
So what should you do?
Understand the difference between a goal and an action towards that goal"When a measure becomes the goal, it stops being a good measure", cautions Goodhart's Law.
We often get confused over what's an input and what's an output. Money, expensive cars, watches, exotic vacations, Instagram-lifestyle, and so on, are all proxies for "a good outcome". They're very easy to measure. They're also very easy to compare. And unfortunately, they have a habit of becoming goals.
Attaining these "good outcomes" is great when they're the byproduct of something deeper, but as soon as we start to chase them as goals they stop measuring our lives accurately.
Maybe you set a goal of being your own boss, having freedom and making money on your own terms. Maybe you begin to do well and in the process you start raking in a ton of money.
Money is much easier to measure than "having freedom" or "being your own boss". And at the end of the day, if you make more money than your friends, you're doing better than them, right?
So, slowly over time, your goal of "be your own boss, have freedom" morphs into "make more money". You spend every waking hour obsessing over how to scale your business or start more businesses. You think leaving money on the table would be failing your goal.
Except... that wasn't your goal to begin with. Your goal was to be your own boss and have freedom, not slave away trying to "make number go up".
Be mindful of your own measures of success — don't let them become the goal. Periodically re-evaluate what you actually want and why.
Ask 'How?'There is a popular concept in root cause analysis called Five Whys. It's used to diagnose the root cause for a defect. Essentially, you just keep asking "ok, why?" until you have arrived at a good answer for what caused the problem.
You can apply a similar pattern for finding plausible inputs for positive outputs. Just like with Five Whys, you start from the outcome, but instead of asking "why?", you keep asking "how?" until you arrive at persuasive inputs.
But remember — don't fool yourself. "The first rule to remember is to not fool yourself, and you're the easiest person to fool", said Richard Feynman.
If you want to run a personal best in a marathon, don't ask "how?" and answer "get an Uber at the 10th kilometer". That would defeat the purpose. Your answers require humility and honesty.
Here's a preventable mistake from my own life where I failed to apply the (Five) Hows. I recently started playing squash more regularly. I really like the game and it's a great workout. The increased frequency of playing lead to a hip injury which has put me out of action for at least two months (and counting).
Given I wanted to continue playing squash, I should've said
- I want to keep playing squash; how?
- by regulating the intensity of each match; how?
- by not diving after every loose ball in order to win; how?
- by hiring an instructor to learn better technique; OK, how else?
- by warming up properly before the matches get intense; how?
- by stretching and doing some light exercises before getting on the court; how?
- by arriving 15 minutes earlier than our scheduled slot; OK, how else?
- etc etc
The difference between Five Whys and Five Hows (yeah, it's called Five Hows now) is that Five Whys is convergent — it tries to get to a single explanation for the outcome. Five Hows, on the other hand, is divergent by nature — there may be multiple different inputs that lead to a favourable outcome. Sometimes it's useful to modify the "how?" to "how else?" to generate more alternative paths.
Focus on what you can controlOne of the pillars of Stoicism is the dichotomy of control, which is the simple idea that some things are within our control and some are not.
Among other things, your beliefs, your actions, your goals, your attitude and your outlook on life are firmly under your control. You can choose your own goals and your own metrics for success. You can choose how you behave and how you treat people. You have choice.
Not under control are other people's opinions, their actions, whether they like you or not, and so on. You could try your best, but it doesn't mean everyone will like what you're doing. In fact, there will be people who won't like you no matter what you do.
There are vastly more things not under your control than there are things that are under your control. If we get too hung up on how the world should be, instead of how it really is, we set ourselves up for failure and misery.
"The best way to achieve success is to deserve it", says Charlie Munger. Focusing on your actions and trying to be better today than you were yesterday — trying to deserve success — is the longest lever you have in your search for success.
🙌🏻Thanks for reading.If you have any comments or feedback on this article, I’d love to hear from you. Come say hi on Twitter or on LinkedIn.



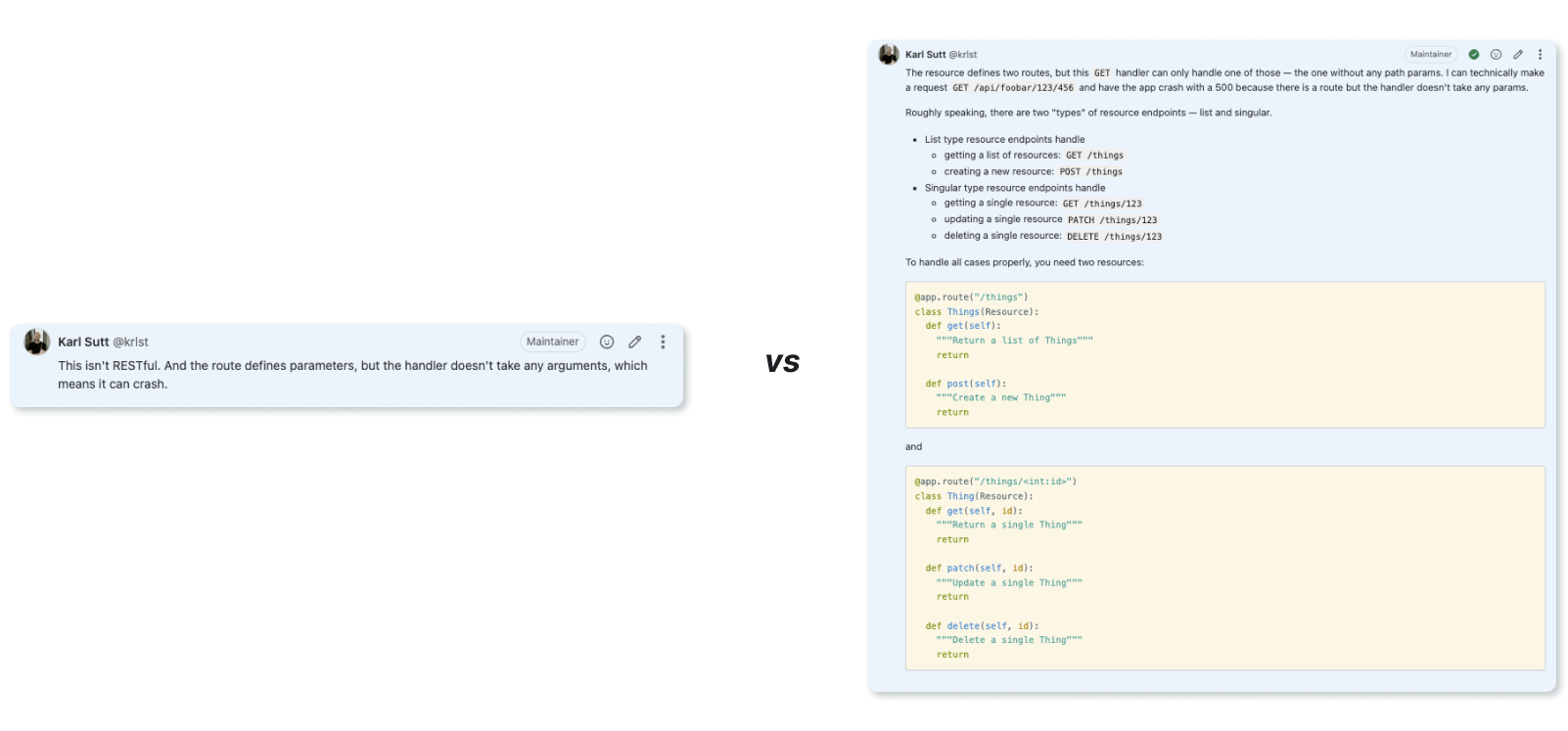








 GitHubkarls
GitHubkarls